어제의 자료에 인구 정보를 같이 넣어서 보자
- 어제 행복도 지수 관련된 사이트/데이터에는 인구정보가 없음
- 메인 데이터 : 기관에서 발표한 행복도 관련 데이터
- 추가 데이터 : 나라별로 인구데이터를 같이 보자(외부 다른 소스에서 찾아서 ) https://data.worldbank.org/indicator/SP.POP.TOTL?end=2021&start=1960&view=chart
# --> 인구 관련 데이터 가지고 옴..
path = '/content/data/population/API_SP.POP.TOTL_DS2_en_excel_v2_4770385.xls'
pop_df = pd.read_excel( path, skiprows=3)
pop_df.head()

2021년도까지 행복도 지수가 있었던 데이터에 인구정보를 같이 보려고 함
data_happy_log.head()

여러 방식 중 하나
- data_happy_log를 기준으로 월드뱅크 연도별 나라의 인구 데이터를 추가 → 칼럼을 추가하고 싶다
- data_happy_log에 pop 컬럼을 추가해서 월드뱅크 인구 데이터를 가져다 붙이기
# 여러 방식 중 하나가...
# data_happy_log를 기준으로,,,월드뱅크 연도별 나라의 인구 데이터를 추가!!!!
# --> 컬럼을 추가하고 싶다!!!!!
# data_happy_log에 pop 컬럼을 추가해서,,,월드뱅크 인구 데이터를 가져다 붙이기!!!
data_happy_log["pop"] = 0
# --> df에 대한 접근 방식 : 정수로 하고자 함!!!
pop_col_indx = data_happy_log.columns.get_loc("pop")
# --> df을 가로줄을 롤링하면서,,,, 인구데이터에 가서,,,그나라 + 그 해 인구 정보가져와서
# 그 가로줄의 pop 컬럼에 기록!!!!
for i in range( len(data_happy_log)):
# i번째 데이터에서 할 일
i_data = data_happy_log.iloc[i, :] # FM
i_data_country = i_data["Country name"] # AM
i_data_year =i_data["year"] # AM
# ====> pop_df에 가서,,,해당하는 정보를 찾아와야 함!!!!
# --> 아래 줄의 코드는,,코드가,,길어져서,,AM
temp = pop_df[ pop_df.loc[:,"Country Name"]==i_data_country].loc[:, str(i_data_year)]
if len(temp) != 0:# --> 원하는 국가의 해당 년도의 인구 정보가 있을 때만...
data_happy_log.iat[i,pop_col_indx] = int(temp.values[0])
print("Done!!")
'''
Done!!
'''
## 체크!!! --> 제대로 매칭이 안 된 데이터를 체크!!!
data_happy_log[data_happy_log["pop"]==0 ] # AM
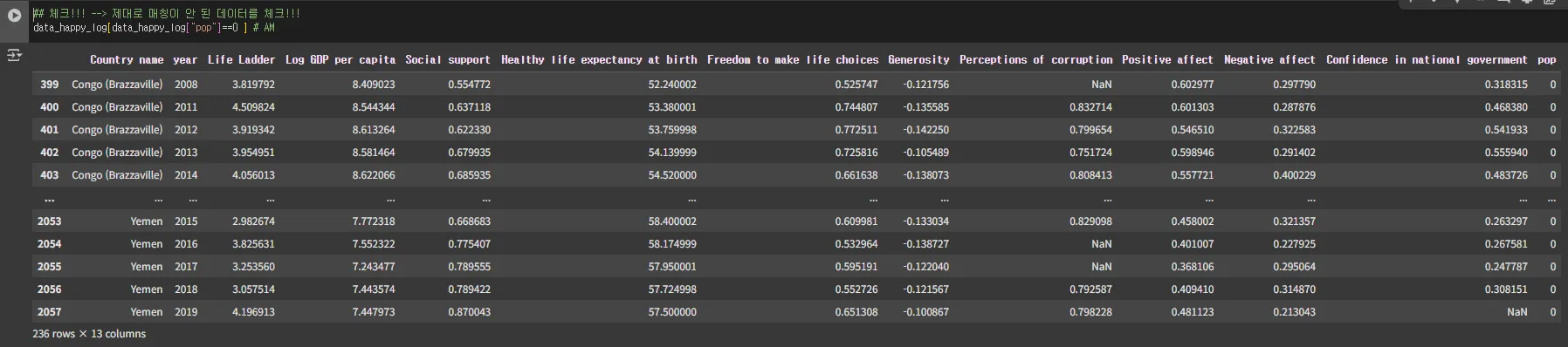
처리가 안 된 샘플이 236개가 있는데 → 데이터의 특성을 보니,,,나라 이름...이슈!!!!
data_happy_log[data_happy_log["pop"]==0 ]["Country name"].unique()
'''
array(['Congo (Brazzaville)', 'Congo (Kinshasa)', 'Egypt', 'Gambia',
'Hong Kong S.A.R. of China', 'Iran', 'Ivory Coast', 'Kyrgyzstan',
'Laos', 'North Cyprus', 'Palestinian Territories', 'Russia',
'Slovakia', 'Somaliland region', 'South Korea', 'Syria',
'Taiwan Province of China', 'Turkey', 'Venezuela', 'Yemen'],
dtype=object)
'''
len(data_happy_log[data_happy_log["pop"]==0 ]["Country name"].unique())
'''
20
'''
data_happy_log[data_happy_log["pop"]==0 ]["Country name"].value_counts()
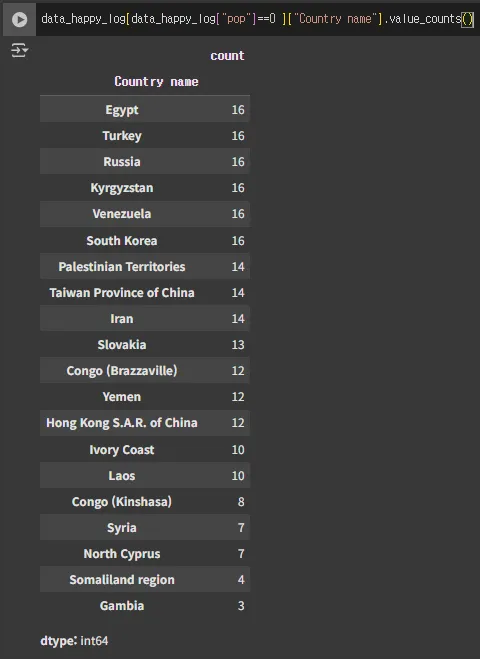


- 어쩔 수 없이 분석자가 직접 확인하면서 룰을 잡아야함 이 부분은 스스로 + 직접 체크해야 함
- dict를 활용해서 구축하는 것이 용이할것
happy_pop_dict = {"Congo (Brazzaville)" : "Congo, Rep.",
"Congo (Kinshasa)":"Congo, Dem. Rep.",
"Egypt": "Egypt, Arab Rep.",
"Gambia":"Gambia, The",
"Hong Kong S.A.R. of China": "Hong Kong SAR, China",
"Iran" : "Iran, Islamic Rep.",
"Ivory Coast": "Cote d'Ivoire",
"Kyrgyzstan": "Kyrgyz Republic",
"Laos":"Lao PDR",
"North Cyprus": "Cyprus",
"Russia" : "Russian Federation",
"Slovakia": "Slovak Republic",
"Somaliland region":"Somalia",
"South Korea": "Korea, Rep.",
"Syria" :"Syrian Arab Republic",
"Turkey":"Turkiye",
"Venezuela":"Venezuela, RB",
"Yemen":"Yemen, Rep."}
happy_pop_dict
'''
{'Congo (Brazzaville)': 'Congo, Rep.',
'Congo (Kinshasa)': 'Congo, Dem. Rep.',
'Egypt': 'Egypt, Arab Rep.',
'Gambia': 'Gambia, The',
'Hong Kong S.A.R. of China': 'Hong Kong SAR, China',
'Iran': 'Iran, Islamic Rep.',
'Ivory Coast': "Cote d'Ivoire",
'Kyrgyzstan': 'Kyrgyz Republic',
'Laos': 'Lao PDR',
'North Cyprus': 'Cyprus',
'Russia': 'Russian Federation',
'Slovakia': 'Slovak Republic',
'Somaliland region': 'Somalia',
'South Korea': 'Korea, Rep.',
'Syria': 'Syrian Arab Republic',
'Turkey': 'Turkiye',
'Venezuela': 'Venezuela, RB',
'Yemen': 'Yemen, Rep.'}
'''
- replace 이런 기능도 있지만 그냥 스타일상 변환 함수를 선호
- 결론은 기존 값을 변경하는 룰
def change_name(co_name):
if co_name in happy_pop_dict.keys():
#변경해야하는 국가명 -> 어떤 것으로 변경할지 value
return happy_pop_dict[co_name]
else:
return co_name
# ++ 혹시 모르니까..기존의 나라 이름을 백업!!!
# --> pop_co_name 새롭게 조작을 하려고 함!!!
data_happy_log["pop_co_name"] = data_happy_log["Country name"]
#data_happy_log["pop_co_name"]
data_happy_log["pop_co_name"] = data_happy_log["pop_co_name"].apply( lambda x:change_name(x))
data_happy_log["pop_co_name"]

# 여러 방식 중 하나가...
# data_happy_log를 기준으로,,,월드뱅크 연도별 나라의 인구 데이터를 추가!!!!
# --> 컬럼을 추가하고 싶다!!!!!
# data_happy_log에 pop 컬럼을 추가해서,,,월드뱅크 인구 데이터를 가져다 붙이기!!!
data_happy_log["pop"] = 0
# --> df에 대한 접근 방식 : 정수로 하고자 함!!!
pop_col_indx = data_happy_log.columns.get_loc("pop")
# --> df을 가로줄을 롤링하면서,,,, 인구데이터에 가서,,,그나라 + 그 해 인구 정보가져와서
# 그 가로줄의 pop 컬럼에 기록!!!!
for i in range( len(data_happy_log)):
# i번째 데이터에서 할 일
i_data = data_happy_log.iloc[i, :] # FM
i_data_country = i_data["pop_co_name"] # AM ---> 수정한 나라 이름,, ******
i_data_year =i_data["year"] # AM
# ====> pop_df에 가서,,,해당하는 정보를 찾아와야 함!!!!
# --> 아래 줄의 코드는,,코드가,,길어져서,,AM
temp = pop_df[ pop_df.loc[:,"Country Name"]==i_data_country].loc[:, str(i_data_year)]
if len(temp) != 0:# --> 원하는 국가의 해당 년도의 인구 정보가 있을 때만...
data_happy_log.iat[i,pop_col_indx] = int(temp.values[0])
print("Done!!")
'''
Done!!
'''
data_happy_log[ data_happy_log["pop"]==0]["Country name"].unique()
'''
array(['Palestinian Territories', 'Taiwan Province of China'],
dtype=object)
'''
# +++= 개인결정 : pop=0인 데이터는 빼고 가자고 결정!!!!!
# ==> 데이터에서 pop=0은 제거!!!!! --> 인덱스 다시 처리!!
data_happy_log = data_happy_log[ data_happy_log["pop"]>0]
data_happy_log.reset_index( inplace=True)
data_happy_log.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2061 entries, 0 to 2060
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 index 2061 non-null int64
1 Country name 2061 non-null object
2 year 2061 non-null int64
3 Life Ladder 2061 non-null float64
4 Log GDP per capita 2036 non-null float64
5 Social support 2048 non-null float64
6 Healthy life expectancy at birth 2023 non-null float64
7 Freedom to make life choices 2029 non-null float64
8 Generosity 1984 non-null float64
9 Perceptions of corruption 1948 non-null float64
10 Positive affect 2037 non-null float64
11 Negative affect 2045 non-null float64
12 Confidence in national government 1846 non-null float64
13 pop 2061 non-null int64
14 pop_co_name 2061 non-null object
dtypes: float64(10), int64(3), object(2)
memory usage: 241.7+ KB
'''
data_happy_log.head()

- 지역에 대한 정보도 같이 붙여서 보자
data_happy_log_pop = pd.merge(data_happy_log, data_happy_2021,
how ="left",
left_on = "Country name",
right_on="Country name") # 기준이 동일하게 컬럼에 있고, 컬럼명도 같은 on ="Country name"
data_happy_log_pop.head()

여러가지 정보들을 평면에 축약하고 싶다
- 색상, 크기, x축, y축, frame 시간
fig = px.scatter( data_happy_log_pop,
x = "Log GDP per capita",
y = "Life Ladder"
)
fig.show()

fig = px.scatter( data_happy_log_pop,
x = "Log GDP per capita",
y = "Life Ladder",
animation_frame = "year",
animation_group = "Country name",
color = "Regional indicator",
size = "pop",
#++++ 기타 꾸민....
template = "plotly_white", # plotly_dark etc
size_max = 50,
hover_name = "Country name"
)
fig.show()

우리가 표현할 수 있는 차원은 2D, 3D
- 샘플에 대한 속성은 정말로 많음, 여러가지가 연관되어서 같이 동작함
- 여러가지 요소들을 함께 보는 부분도 필요하다 → 탐색을 할 때
- 다시 이것을 태블로로 옮겨서 하는 것은 불편하다 → ploty 이용할 수 있다 → 단, 다 코드로 해야해서 좀 귀찮을 수 있음 → 재현이 용이함
- 내가 보이고자 하는 것들에 대한 효과적인 그래프가 무엇인지 ⇒ Data Visualization 파트 있음 간단하게 파이썬 생태계에서 데이터 처리하면서 시각화도 하고
- 단순히 기술적인 부분 *** 처리할 것들에 대해서 최대한 노가다를 줄일 수 있는 규칙들을 잘 체크
- 생각보다 이 정도는 정말로 깨끗한 데이터 스타일 실제로 가면 애매한 데이터도 정말 많다
✨스스로 데이터 핸들링이 자유로워야 함
'데이터분석 > Pandas' 카테고리의 다른 글
| [Python] Pandas _ EDA _ 04 worldhappy (4) | 2025.08.28 |
|---|---|
| [Python] Pandas _ EDA _ 03 gpt (1) | 2025.08.27 |
| [Python] Pandas _ EDA _ 02 titanic (2) | 2025.08.27 |
| [Python] Pandas _ EDA _ 01 telecom (2) | 2025.08.26 |
| [Python] Pandas 15 _ curl (1) | 2025.08.25 |