데이터 처리하는 관점
!gdown 1GUltwE6D9Cv90AP8nfO_kezO0d7TAtg7
'''
Downloading...
From: <https://drive.google.com/uc?id=1GUltwE6D9Cv90AP8nfO_kezO0d7TAtg7>
To: /content/titanic_train.csv
100% 60.3k/60.3k [00:00<00:00, 66.1MB/s]
'''
# 데이터 핸들링
import pandas as pd
import numpy as np
# 간단하게 시각화
import matplotlib.pyplot as plt
import seaborn as sns
# csv 파일을 불러오시면 됨!!!!
# ==> 혹시 특정 칼럼이 가로 인덱스로 사용할 수 있는게 보장이 되어있다면
# 불러들이면서, 가로 인덱스를 지정하는 경우! set_index ~~
# ==> 파일을 불러올 때 필요한 기능이 있어서 편히 할 수 있으면 파라미터 메뉴얼
path = '/content/titanic_train.csv'
data = pd.read_csv(path, index_col="PassengerId") #set_index 대신 불러올 때 지정 가
data.head()

data.tail()

data.loc[1,:] # --> 가로 내가 만든 인덱스 기준 1로 선택
#위에서 데이터 불러올 때 PassengerId로 정수인덱스 만들었음

data.iloc[1,:] # 태생적인 인덱스

data.info()
#비어있는 거 체크

Age가 제일 애매한 사항
- 이 친구들에 대해서 누락된 데이터를 일단 확인해보자
- SQL ) select ~~ from ~~ where age is null;
data.loc[ data.loc[:,"Age"].isnull() , :]

len(data.loc[ data.loc[:,"Age"].isnull() , :])/ len(data)
'''
0.19865319865319866
'''
# 전체 컬럼들에 대해서 돌아가면서 누락비율 체크!!!!
for col in data.columns:
print(col, str(len(data.loc[ data.loc[:,col].isnull() , :])/ len(data)))
# --> 컬럼이 엄청 많지 않고 십여개 있으니까 이렇게 해도 눈에 보임
# 수백개 수천개 컬럼은 이렇게 하면 안 보임
# ==> 컬럼이름과 결측치에 대한 dict/df을 만들어서 + sort ==>
'''
Survived 0.0
Pclass 0.0
Name 0.0
Sex 0.0
Age 0.19865319865319866
SibSp 0.0
Parch 0.0
Ticket 0.0
Fare 0.0
Cabin 0.7710437710437711
Embarked 0.002244668911335578
'''
여러 조건에 대한 필터링
- 조건
- Embarked = “C”
- Fare → 200초과
- ⇒ 위 두 조건을 만족하는 데이터를 추출해보세요
# --> 길어지니까 간단하게...
#data["Embarked"]=="C"
#data["Fare"]>200
data.loc[(data["Embarked"]=="C") & (data["Fare"]>200) , : ]

#위의 필터링 된 결과 중에서 Fare를 기준으로 내림차순으로 보자
data.loc[(data["Embarked"]=="C") & (data["Fare"]>200) , : ].sort_values(
by = ["Fare"], ascending = False
)
#요점 : 탐색하는 과정에서는 대상이 DF이면
# 눈에 보이는 코드 결과가 DF이면, DF에서 하던 모든 것들이 적용된다
# 눈에 보이는 결과에서 다음 변형/ 내용들을 탐색
# 코드 자체가 계속...끌고가는 형태가 나올 수 있음

기존의 값을 내가 원하는 대로 변경/ 재조정 ( sql에서 case when과 같은 역할 )
- 이게 ML의 핵심 → Feature 어떻게 잘 만들고 조정하냐
- 모델의 성능을 좌우함
- EDA + 도메인 지식 ⇒ ML 모델링
- Age
- 재조정을 하려고 함
- (원래 EDA해야하지만 그냥 하겠다)
- 30미만 : 1 30이상 ~ 55미만 : 2 55이상 ~ : 3 ⇒ 통년, 그 도메인에서 주로 사용하는 기준을 사용하거나 ⇒ 나의 데이터의 분포나 EDA를 기반으로 조정해도 됨
pandas ) m1
- apply + lambda + if를 여러
pandas ) m2
- apply + 내가 직접 함수를 만들자 ( 복잡한 처리, 다른 패키지)
# --> lambda + if
data.loc[:,"Age"].apply(lambda x : 1 if x < 30 else ( 2 if x < 55 else 3 ))
# --> NaN : 3번으로 결측값들이 처리될 여지들이 있음
# 결측값에 대한 처리를 먼저 하고 해야 진행이 유리함

#m2) 나이를 변경하는 함수
# --> 입력 : age
# 출력 : 위에 지정한 규칙대로 변경된 1~3값
def age_cat(age):
if age < 30:
return 1
elif age < 55 :
return 2
else:
return 3
age_cat(3)
'''
1
'''
data.loc[:,"Age"].apply( lambda x : age_cat(x)) #sum(x)

data.loc[:,"Age"].apply(age_cat)

[age_cat(age)for age in data.loc[:, "Age"]]
'''
[1,
2,
1,
2,
2,
3,
2,
1,
1,
1,
1,
3,
1,
2,
1,
3,
1,
3,
2,
3,
2,
2,
1,
1,
1,
2,
3,
1,
3,
3,
2,
3,
3,
3,
1,
2,
3,
1,
1,
1,
2,
1,
3,
1,
1,
3,
3,
3,
3,
1,
1,
1,
2,
1,
3,
3,
1,
1,
1,
1,
1,
2,
2,
1,
3,
3,
1,
1,
1,
1,
2,
1,
1,
1,
2,
1,
3,
3,
1,
2,
1,
1,
3,
1,
1,
2,
1,
3,
1,
1,
1,
1,
2,
1,
3,
3,
3,
1,
2,
2,
1,
3,
1,
2,
2,
1,
1,
3,
2,
3,
2,
1,
1,
1,
1,
1,
3,
1,
1,
1,
1,
3,
2,
2,
2,
1,
3,
1,
3,
2,
2,
1,
2,
1,
1,
1,
1,
2,
1,
1,
3,
1,
1,
1,
1,
1,
1,
1,
2,
2,
2,
1,
3,
2,
3,
2,
1,
2,
3,
3,
2,
2,
1,
1,
1,
1,
3,
2,
3,
1,
3,
1,
1,
1,
3,
1,
3,
2,
2,
2,
3,
3,
1,
1,
1,
3,
3,
2,
2,
2,
2,
1,
1,
1,
2,
3,
3,
2,
3,
1,
1,
3,
2,
2,
1,
1,
2,
1,
1,
2,
1,
2,
1,
2,
3,
2,
1,
2,
2,
2,
1,
1,
2,
3,
2,
1,
1,
1,
1,
3,
2,
1,
3,
1,
1,
3,
2,
1,
1,
2,
3,
3,
1,
1,
2,
2,
1,
1,
2,
2,
3,
1,
3,
2,
2,
1,
3,
2,
2,
2,
3,
1,
2,
2,
3,
2,
1,
1,
3,
2,
3,
1,
2,
2,
3,
3,
2,
3,
1,
2,
3,
1,
1,
1,
3,
2,
2,
1,
2,
1,
1,
1,
2,
1,
1,
3,
1,
1,
3,
2,
3,
3,
1,
3,
3,
1,
3,
1,
2,
2,
1,
1,
1,
1,
2,
1,
1,
2,
2,
2,
1,
1,
2,
1,
3,
2,
3,
2,
2,
1,
3,
2,
2,
1,
3,
3,
1,
2,
2,
2,
1,
1,
1,
1,
2,
1,
2,
3,
1,
2,
1,
3,
1,
1,
3,
1,
1,
2,
3,
3,
2,
1,
2,
2,
3,
2,
3,
3,
3,
1,
1,
1,
1,
1,
1,
3,
1,
1,
1,
1,
2,
1,
2,
2,
3,
1,
1,
2,
3,
1,
2,
1,
1,
1,
1,
1,
2,
2,
1,
1,
2,
1,
1,
1,
1,
2,
2,
1,
1,
3,
3,
3,
2,
3,
2,
3,
2,
1,
2,
1,
3,
1,
1,
1,
1,
3,
1,
1,
3,
2,
1,
3,
2,
1,
2,
1,
1,
1,
3,
2,
2,
1,
1,
1,
3,
1,
1,
2,
1,
2,
2,
3,
2,
2,
3,
1,
3,
3,
2,
3,
2,
2,
2,
2,
3,
2,
3,
3,
3,
1,
3,
2,
2,
1,
1,
3,
2,
1,
1,
1,
1,
3,
2,
3,
1,
3,
2,
3,
2,
1,
3,
1,
3,
3,
1,
3,
2,
3,
1,
1,
1,
1,
3,
2,
1,
1,
2,
3,
1,
1,
1,
3,
2,
2,
1,
2,
2,
3,
2,
2,
2,
1,
3,
2,
3,
2,
2,
3,
2,
1,
1,
3,
1,
3,
2,
1,
2,
2,
3,
1,
2,
1,
1,
2,
2,
3,
1,
3,
2,
1,
1,
1,
3,
1,
1,
3,
2,
3,
2,
2,
3,
2,
1,
3,
3,
1,
1,
1,
3,
2,
3,
2,
2,
3,
1,
1,
2,
2,
3,
2,
1,
2,
2,
2,
3,
1,
2,
3,
1,
3,
2,
2,
2,
3,
2,
2,
3,
2,
3,
2,
1,
3,
3,
2,
2,
2,
2,
1,
1,
2,
2,
3,
3,
3,
2,
1,
2,
1,
1,
1,
1,
2,
1,
1,
1,
3,
3,
1,
1,
3,
3,
2,
2,
3,
1,
1,
2,
2,
2,
3,
1,
1,
1,
3,
1,
2,
1,
3,
3,
1,
3,
1,
1,
3,
1,
1,
3,
2,
1,
3,
2,
2,
2,
2,
1,
2,
1,
3,
2,
3,
2,
2,
3,
2,
3,
1,
1,
1,
2,
2,
3,
1,
1,
1,
3,
1,
1,
1,
1,
1,
2,
1,
3,
1,
3,
2,
2,
3,
2,
2,
1,
2,
1,
1,
1,
2,
2,
2,
1,
3,
1,
3,
2,
1,
2,
1,
2,
1,
3,
2,
1,
1,
2,
2,
1,
1,
2,
3,
1,
1,
1,
1,
3,
1,
1,
1,
2,
2,
3,
3,
3,
2,
1,
1,
2,
3,
1,
2,
1,
2,
1,
1,
2,
1,
2,
1,
1,
1,
2,
2,
3,
2,
1,
2,
1,
2,
3,
2,
3,
2,
1,
2,
3,
3,
2,
1,
3,
1,
3,
2,
1,
1,
1,
3,
1,
1,
1,
1,
1,
2,
3,
1,
3,
3,
1,
2,
2,
2,
2,
2,
2,
2,
1,
1,
1,
2,
2,
1,
2,
2,
1,
2,
2,
1,
2,
3,
1,
2,
2,
1,
2,
1,
2,
1,
1,
3,
3,
1,
3,
3,
1,
1,
3,
1,
1,
2,
1,
3,
2,
3,
1,
1,
2,
2,
1,
2,
3,
2,
1,
3,
1,
3,
1,
1,
2,
1,
2,
2,
1,
3,
2,
1,
2,
3,
1,
2,
1,
2,
3,
1,
1,
2,
2,
2,
1,
1,
1,
1,
3,
3,
1,
2,
1,
1,
1,
2,
1,
1,
3,
1,
2]
'''
→ 굳이 lamba 함수에 무리하지 말자
→ 복잡하거나 그러면 그냥 편하게 본인이 원하는 변경에 대한 함수를 작성하자
탐색을 하는 과정에서 간단히 그래프로 보자
- pandas의 matplotlib에 대한 그래프를 사용할 수 있도록 기능을 만들어둠
- 완벽하게 동일한 모든 기능까지는 아님
- 간단히 자주 사용되는 기능들 몇가지를 사용할 수 있게 해놓음
data.loc[:,"Sex"].value_counts() #표로 나오니까 좀 안 직관적이야

data.loc[:,"Sex"].value_counts().plot(kind="bar")
# pandas 메뉴얼 : line, bar, barh, kde, hist, box etc...

#얘네도 꾸미기 가능
data.loc[:,"Sex"].value_counts().plot(kind="bar", color = ["r","g"])

data.loc[:,"Sex"].value_counts().plot(kind="bar", color = ["r","g"], title = "F/M counts")

https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html
- 판다스에서 데이터를 핸들링 하면서 눈에 보이는 Series/DataFrame을 바로 그래프로 변경해서 볼 수 있다.
- 단, 모든 종류는 지원하지 않음
데이터 변형
pivot_table, groupby
- 목적 : 카운팅
- 2개의 변수들에 대해서 오로지 “카운팅/갯수” 으로 채우자 → crosstable
- crosstab( 가로, 세로 )
- 나의 기준으로 수집된 샘플의 분포
pd.crosstab(data["Pclass"], data["Sex"])

seaborn 그래프로 그려보자
- data, 가로x, 세로y, 구별hue etc..
sns.boxplot( x= data["Survived"], y= data["Age"])

sns.boxplot(data=data, x = "Survived", y = "Age")
#이게 더 seaborn 스러운 코드

- 객실 등급별로 요금 체크 -> 눈에 두드러지는 차이 보기 위해
#객실 등급별로 요금 체크 -> 눈에 두드러지는 차이 보기 위해
sns.boxplot(data=data, x ="Pclass", y = "Fare")

- 1등석의 아주 고가들은 알겠고, 1등, 2등, 3등석의 차이들에 대한 것들을 줌해서 보고싶다
- ⇒ 아웃라이어를 제거하고 보면 어떨까 → 필터링
sns.boxplot( data= data.loc[data["Fare"]<data["Fare"].quantile(0.95) , : ],
x="Pclass", y="Fare")

- 그래프를 그릴 때도 필터링을 사용해서 볼 수 있다 → DF면 되니까!
객실별로 승객의 수를 그래프로 그려보자
data.loc[:,"Pclass"].value_counts()

data.loc[:,"Pclass"].value_counts().plot(kind="barh")

# seaborn패키지 : countplot
sns.countplot( data= data, x="Pclass")

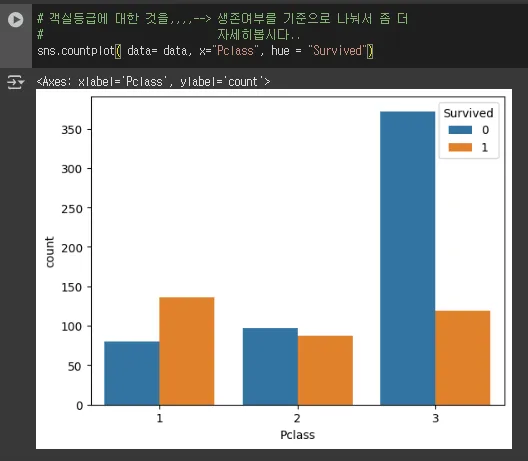
# 객실등급에 대한 것을,,,,--> 생존여부를 기준으로 나눠서 좀 더
# 자세히봅시다..
sns.countplot( data= data, x="Pclass", hue = "Survived")
여러개의 그래프를 1개로 통합해서 보자
- 2개의 그래프를 1개의 판에 합쳐서 그려보자
- 왼쪽 : 객실별 승객수 → pandas plot
- 오른쪽 : 객실별 생존자/사망자 수 → seaborn → countplot
- ⇒ 1개 판에 matplotlib.pyplot에서 subplots
# 1) 전체 판 세팅
fig, axes = plt.subplots(nrows =1, ncols = 2)
# 2) 왼쪽 : 객실별 승객수 → pandas plot
data.loc[:,"Pclass"].value_counts().plot(kind="barh", ax = axes[0], color="g")
# 3) 오른쪽 : 객실별 생존자 수 → seaborn → countplot
sns.countplot(data = data, x = "Pclass", hue = "Survived", ax = axes[1])
# ++ 꾸밈 opt
axes[1].set_title("Pclass vs Survived")
# ++ 판 정리
fig.tight_layout()

pandas를 가지고 데이터 핸들링을 잘 해야함
- 실제로는 상당히 지저분하고 처리할 것들이 빡세다
- 전처리 + 가공 중요한 입장이 됨
- 진짜로 원하는대로 잘 변경이 되었는지 더블체크 꼭 하자
내일은 좀 더 지저분한 경우에 대한 핸들링을 할 것
'데이터분석 > Pandas' 카테고리의 다른 글
| [Python] Pandas _ EDA _ 04 worldhappy (4) | 2025.08.28 |
|---|---|
| [Python] Pandas _ EDA _ 03 gpt (1) | 2025.08.27 |
| [Python] Pandas _ EDA _ 01 telecom (2) | 2025.08.26 |
| [Python] Pandas 15 _ curl (1) | 2025.08.25 |
| [Python] Pandas 14 _ groupby (3) | 2025.08.25 |