앞에서 한 pivot_table과 동일한 일 ⇒ 데이터 변경
- 내가 직접 판을 짜서 보겠다 (pivot_table)
- 내가 데이터들을 묶어가면서 보겠다(sql) → groupby
- 묶어가면서 무엇을 볼지 (집계/대표) 처리하는 방식 : sql
ex) 전교생의 성적이 있는 데이터셋 수집! 몇 반, 누구, 몇 점인지 ⇒ 반별로 묶어서 보자
- pivot_table : 가로기준 (학생 → 반), 세로 (점수 → 평균 aggfunc)
- sql) select avg(zumsu) from data group by class ;
- pandas groupby) df.groupby(by = “class”).agg(”집계처리..”)
import numpy as np
import pandas as pd
!gdown 1PqRm5x29Lqxt_q8tFhYKvcsAwDxmV6A2
'''
Downloading...
From: <https://drive.google.com/uc?id=1PqRm5x29Lqxt_q8tFhYKvcsAwDxmV6A2>
To: /content/10_phone_data.csv
100% 40.6k/40.6k [00:00<00:00, 50.5MB/s]
'''
path = '/content/10_phone_data.csv'
data = pd.read_csv(path, sep=",") #뭐로 구분되는 지는 일단 sep 안 쓰고 기본으로 넣었다가, 이상하게 들어가면 자기가 직접 찾는 수밖에는 없음
data.head()

*** 자주 사용되는 기능 : 그 컬럼에 어떤 값이 몇 개가 있어요??
df["~~~"].value_counts()
data.head()

data.loc[:, "item"].value_counts()
# +++ item에 있는 유니크한 값들 종류 & 개수
# +++ 개수에 대한 내림차순 자동 정렬
# value_counts ===> count + sort

type(data.loc[:, "item"].value_counts())
'''
pandas.core.series.Series
'''
# item 에서 최빈값에 대한 항목의 이름은 뭐에요??
data.loc[:, "item"].value_counts()
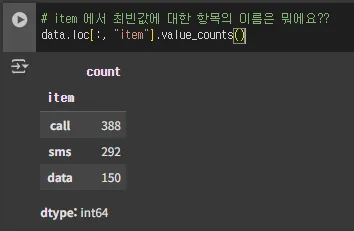
# item 에서 최빈값에 대한 항목의 이름은 뭐에요??
data.loc[:, "item"].value_counts().index[0]
'''
call
'''
# item에서 제일 많은 항목의 카운트는 얼마에요?
data.loc[:, "item"].value_counts().values[0]
'''
np.int64(388)
'''
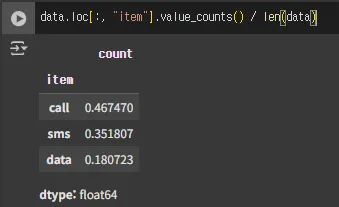
# 항목별 갯수도 보지만 ...비율로도 봄
data.loc[:, "item"].value_counts(normalize = True)

data.loc[:, "item"].value_counts() / len(data)
item 중에서 전화 call인 경우에 대해서 수집된 데이터의 총 사용시간의 합 duration : sum
data.loc[ data.loc[:,"item"] =="call", "duration"]

data.loc[ data.loc[:,"item"] =="call", "duration"].sum()
# select duraion from data where item ="call"
'''
np.float64(92321.0)
'''
# 속도이슈가 있어서 비추이긴 하지만 되기는 함
data[data["item"]=="call"]["duration"] ## 얘도 위랑 결론은 같지만 최대한 피하세요!

month 컬럼에 대해서 종류 + 갯수
# month 컬럼에 대해서 종류 + 갯수
data.loc[:, "month"].value_counts()

group by 기준 -> month
- 830개 개별 사용 데이터 기준 셋
- 5개의 월을 기준으로 바꿔서 보려고 함
- ⇒ 샘플 단위 : 월
***** 수집을 하는 메인 데이터의 레벨 : 큰 범위로는 분석이 가능함**
- 메인 데이터(일) → (주, 월, 분기, 년도) → (시간대별로는 분석 분가능)
- 메인 데이터(분기별 통계) → (년도 OK) → (날짜, 요일별 XXXXX)
⇒ 왜 이런 현상 벌어짐?? → 작은 단위로 들어가야 보일 수 있는데
data.groupby(by="month")
'''
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7beeede5b710>
'''
data.groupby(by="month").groups
'''
{'2014-11': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, ...], '2014-12': [228, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, ...], '2015-01': [381, 386, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 409, 410, 411, 412, 413, 414, 415, 416, 417, 418, 419, 420, 421, 422, 423, 424, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446, 447, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, ...], '2015-02': [577, 586, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 622, 623, 624, 625, 626, 627, 628, 629, 630, 631, 632, 633, 634, 635, 636, 637, 638, 639, 640, 641, 642, 643, 644, 645, 646, 647, 648, 649, 650, 651, 652, 653, 654, 655, 656, 657, 658, 659, 660, 661, 662, 663, 664, 665, 666, 667, 668, 669, 670, 671, 672, 673, 674, 675, 676, 677, 678, 679, 680, 681, 682, 683, 684, 685, 686, 687, 688, 689, 690, 691, ...], '2015-03': [729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 754, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, ...]}
'''
data.groupby(by="month").groups.keys()
'''
dict_keys(['2014-11', '2014-12', '2015-01', '2015-02', '2015-03'])
'''
data.loc[:,"month"].value_counts().index
'''
Index(['2014-11', '2015-01', '2014-12', '2015-02', '2015-03'], dtype='object', name='month')
'''
data.loc[:,"month"].unique()
'''
array(['2014-11', '2014-12', '2015-01', '2015-02', '2015-03'],
dtype=object)
'''
data.groupby(by="month").head(2)
# ==> groupby를 하면 묶여 있어서 안 보이지만
# 하나의 df라고 생각하고 할 일들을 작성하면 됨
# 단, 동작이 모든 group에 적용
# head(2) --> df에서 앞의 2개를 보여주세요 기능
# 모든 group에 적용!!!

data.groupby(by="month")["duration"].mean()
# sql ) select avg(duration) from data group by month;

# 주의!!!
data.groupby(by="month").loc[:,"duration"]
#pandas에서 groupby를 하고 특정 컬럼 지정하기 위해 loc 쓰지마라
#[보고자하는 컬럼들] 지정!!!하기 위해 ==> loc/iloc XXX 사용 불가

# 이 동일한 결과를 pivot_table로 만들어보세요!!!!
# sql) select avg(duration) from data groiup by month;
pd.pivot_table( data,
index=["month"],
values=["duration"],
aggfunc = ["mean"])

최신 pandas 에서는
data.groupby(by="month")["duration"].mean()
이런 스타일보다는 명시적으로 agg(”mean”)
# ++ 최신 pandas에서는
# data.groupby(by="month")["duration"].mean()
# 이런 스타일보다는, 명시적으로 agg("mean"
data.groupby(by="month")["duration"].agg("mean") # FM

item의 항목이 call인 경우에 한해서(전화통화) ⇒ network 통신사 별로 duration 총 합을 보자 ⇒ 통신사별로 전화 사용에 대해서 차이가 있는지
# 830건 --> call 380 ---> 통신사별로 묶어서,,,duration
data.loc[ data.loc[:,"item"]=="call",:].groupby("network")["duration"].agg("sum")

묶는 기준 당연히 여러개도 가능함
- pivot_table에서 index ⇒ 여러개 [”manager”,”rep”]
- groupby의 기준도 여러개 가능함
# + 묶는 기준 당연히 여러개도 가능함!!!
# --> pivot_table에서 index ==> 여러개 ["manager","rep"]
# --> groupby의 기준이 여러개가 가능함!!!
data.groupby( by=["month","item"]).head(2)

# --> 카운팅 : 아무거나(pk) 카운팅!!!!!!!! count(*), count(1), count(pk)
# count(필드명---null없는)
data.groupby( by=["month","item"])["date"].count()

+++보려고 하는 항목이 각기 존재할 때
- sql ) select first(date), sum(duration) from data group by month, item;
# +++ 보려고 하는 항목이 각기 존재할 때...
# sql) select date, sum(duration) from data
# group by month, itenm;
data.groupby( by=["month","item"]).agg(
{
"date":"first",
"duration":"sum"
}
)

*** EDA를 하는 핵심
- 내가 수집한 데이터 표면을 보는 것
-
- 내가 원하거나 보고자 하는 것들을 중심으로 보면서 **유의미한 것들을 발견하는 것이 중
- **(**코드는 그냥 gpt 사용하면 거의 다 원하는 것들을 할 수 있음)
- 내가 어떻게 끌고가려는 방향/ 호기심/ 도메인 지식이 중요함
- 단점은 … 시간대비 가성비가 좋지 않다…..(시간이 단축되려면 일반적으로 처리해야함)
'데이터분석 > Pandas' 카테고리의 다른 글
| [Python] Pandas _ EDA _ 01 telecom (2) | 2025.08.26 |
|---|---|
| [Python] Pandas 15 _ curl (1) | 2025.08.25 |
| [Python] Pandas 13 _ pivot (1) | 2025.08.25 |
| [Python] Pandas 12 _ na (1) | 2025.08.25 |
| Selenium 02 _ dart_selenium (0) | 2025.08.22 |