데이터를 이리저리 보기 위해서 (탐색의 기본 조건)
- 수집된 데이터를 그대로 보는 것은 1차원적인 부분
- 수집된 데이터를 기반으로 이리 저리 가공하면서 탐색
- 수집된 데이터를 본인 기준(보고자 하는 사항)으로 변경
기준
- 데이터가 수집된 기준X
- 내가 보고자하는 기준 ( 기존 컬럼, 직접 생성한 컬럼 )으로 바라보자
이런 접근 방식 중 가장 대표적인 것 ⇒ 엑셀의 피벗테이블
- 샘플 단위가 아니라 속성/기준으로 바라보자
- EDA의 가장 기본적인 부분 중 하나
pandas에서 이러한 기능
- pivot_table (딱 세팅)
- groupby (묶어가면서 순차적으로)
- ⇒ 양쪽의 결과물은 동일함, 어떻게 접근하느냐의 차이
import numpy as np
import pandas as pd
# 11sale 관련 데이터
!gdown 1g3QxQfKc7Qcrhwb2rpz0aXbg_uojC_A7
'''
Downloading...
From: <https://drive.google.com/uc?id=1g3QxQfKc7Qcrhwb2rpz0aXbg_uojC_A7>
To: /content/11_sales-funnel.xlsx
100% 5.68k/5.68k [00:00<00:00, 11.5MB/s]
'''
path = '/content/11_sales-funnel.xlsx'
# ==> 엑셀 : 파일을 열 때 : 명시적으로 시트명을 지정!!!
# Sheet1
data = pd.read_excel(path, sheet_name ="Sheet1")
data.head()

데이터 설명
→ 계약 매출 데이터
- account : 고객의 계좌번호
- name : 고객의 이름
- Rep : 영업 담당자 (실무 영업사원)
- Manager : 영업 담당자의 팀장
- product : 판매한 물건
- Quantity / price : 판매한 물건의 수량 / 가격
- Status : 현재 주문 상태
기존 데이터
- 매출 발생할 때마다 이벤트 중심의 로그 데이터
- ⇒ 매출 관련 로그 데이터
- 목적
- 매출 관련된 데이터를 바탕으로 인사 평가를 해보자
- ⇒ 인사팀장의 관점으로 바라보려고 함
pivot_table을 활용해서 새롭게 데이터 판을 짜보자
- 가로에 무엇을 세팅할까 ⇒ 대상/샘플
- 세로에 무엇을 세팅할까 ⇒ 어떤 속성
- 1/2 만들어진 새로운 공간을 어떻게 채울까 ( Default → mean ) ⇒ 여러개의 원본데이터들이 1칸의 공간으로 들어가는 경우, 집계처라가 기본 스타일이 됨
Q1 . 영업 팀장들에 대해서 본인 팀에 대한 매출액을 보고싶다! ⇒ 영업 팀장의 평가 → 오로지 매출로 ⇒ 일단은 값들에 대해서 특별하게 지정하지 않으면 → 평균으로
pd.pivot_table( data,
index = ["Manager"],
values =["Price"])
# --> price의 함정은 평균 매출액이지, 누적액은 아님! (그것이 맹점)

영업 팀장 별로 가격에 대한 평균보다 실제 매출이 더 중요하지 않을까.. ⇒ price에 대한 총합
# --> 영업 팀장별로,,,가격에 대한 평균보다 실제 매출!!!
# ===> pirce에 대한 총합..
pd.pivot_table( data,
index = ["Manager"],
values =["Price"],
aggfunc=["sum"])

단순 총 매출액만으로 보고 판단하려고 했는데,, → 꾸준한 영업 활동을 하면서 이룬 매출액인지.. → 운이 좋게 큰 고객을 하나 잡아서 이룬 매출액인지
# 단순 총 매출액만으로 보고 판단하려고 했는데,,
# ==> 꾸준한 영업 활동을 하면서 이룬 매출액인지..
# 운이 좋게 큰 고객을 하나 잡아서 이룬 매출액인지..
pd.pivot_table( data,
index = ["Manager"],
values =["Price"],
aggfunc=["sum", "count"])

팀장-팀원을 같이 보면서,,,위의 사항을 보려고 함!
→ 팀장이 팀원들의 매출액을 잘 관리를 하는지 보자
→ 샘플 기준 : 팀장-팀원
pd.pivot_table( data,
index = ["Manager", "Rep"],
values =["Price"],
aggfunc=["sum", "count"])

Q2. 상품 기획팀의 입장에서 매출에 대해서 바라봄 → 구체적으로 어떤 회사의 상품이 팔리는지가 중요한 사항 → + 영업 담당자들이 어떻게 파는지도 같이 보자
pd.pivot_table( data,
index = ["Manager", "Rep"],
values =["Price"], # <-- 주로 수치형 컬럼
columns = ["Product"], # <-- 주로 카테고리형 컬럼
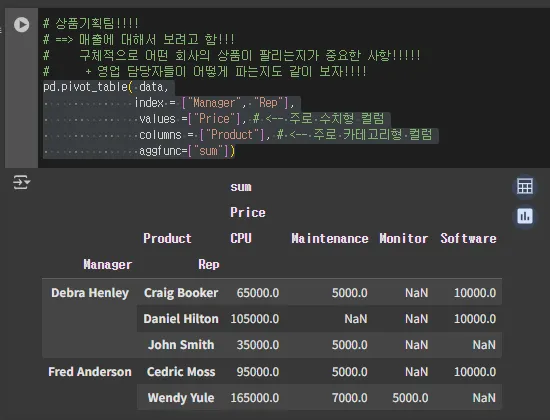
- 회사의 주력 매출 : CPU
- monitor는 왜 영업 사원들이 잘 안 팔까?
- 우리 상품이 문제가 있어서 그런지
- 영업 인센티브가 모니터는 적어서 그런지 등…
- 묶음 상품에 대한 구성을 어떻게 하면 좋을지
+++ 더 많은 기준으로 표를 만들게 되면 원본 데이터에 해당하지 않은 칸이 존재하게 됨
# +++ 더 많은 기준으로 표를 만들게 되면,,
# 원본 데이터에 해당하지 않은 칸이 존재하게 됨!!!
pd.pivot_table( data,
index = ["Manager", "Rep"],
values =["Price"], # <-- 주로 수치형 컬럼
columns = ["Product"], # <-- 주로 카테고리형 컬럼
aggfunc=["sum"],
fill_value=0data.shape

+++ 내가 보고자 하는 항목 : amount 수량
pd.pivot_table( data,
index = ["Manager", "Rep"],
values =["Price","Quantity"], # <-- 주로 수치형 컬럼
columns = ["Product"], # <-- 주로 카테고리형 컬럼
aggfunc=["sum"],
fill_value=0)

++총계/총합 (일광 집계 처리 방식)
# + 총계/ 총합
pd.pivot_table( data,
index = ["Manager", "Rep"],
values =["Price","Quantity"], # <-- 주로 수치형 컬럼
columns = ["Product"], # <-- 주로 카테고리형 컬럼
aggfunc=["sum"],
fill_value=0,
margins=True)

각 항목에 원하는 집계 처리 방식 지정
pd.pivot_table( data,
index = ["Manager", "Rep"],
values =["Price","Quantity"], # <-- 주로 수치형 컬럼
columns = ["Product"], # <-- 주로 카테고리형 컬럼
aggfunc={
"Price" : ["mean", "sum"],
"Quantity" : ["sum"]
}, # <--- 원하는 항목에 집계처리방식지정!!
fill_value=0) # <-- margin은 mean에 의미가 없어서 skip

data.shape
'''
(17, 8)
'''
- 수집된 17.8 이라는 모양으로 보는 것이 아니라.. 내가 원하는 기준에 의해서 새로운 모양으로 재형성해서 보는 방법에 대해서!!
- *** 새롭게 2차원의 판을 짜보자!!! ***
- 가로 index : 어떤 기준으로 샘풀/레코드를 볼지!!! --> 영업 담장자, 상풍 etc
- 세로 values + 항목별로 쪼개서 (columns) : 볼 항목/볼 속성!!! → aggfunc ; 새롭게 짜인 파에 원본 데이터에서 값을 어떻게 집계처리!!!
- 수집된 데이터에 숨겨져 있는 속성/ 내용 이런 것들을 탐색하는 기본!!!!!
- +++ 이렇게 이리 저리 봐도,,,별 소득이 없는 경우가 다반사 입니다!!!
- 잘 알아야 함!! 도메인 지식!!!!! 아이디어+ 방향성으로 도출!!!
'데이터분석 > Pandas' 카테고리의 다른 글
| [Python] Pandas 15 _ curl (1) | 2025.08.25 |
|---|---|
| [Python] Pandas 14 _ groupby (3) | 2025.08.25 |
| [Python] Pandas 12 _ na (1) | 2025.08.25 |
| Selenium 02 _ dart_selenium (0) | 2025.08.22 |
| Selenium 01 _ selenium 설치 및 실행 (0) | 2025.08.22 |