목적
- API를 활용해서 명시적으로 데이터를 요청/받는 작업!!
- 통신 http를 활용해서, 정의된 api의 서버/요청사항에 대해서 요청/받아서 처리
- → 유료로 api를 제공하는 경우도 많이 있음!! ( + 비용!!! 돈!!! ) → 접속이나 속도나 이런 부분에 있어서,,크게 구애받지 않음!! 돈 충분하면 상관 없음
내가 원하는 정보가 api가 아닌 사이트에서 그냥 긁어야 하는 경우 있음
- case by case
- 그쪽에서 얼마나 보안이나 데이터 보호에 신경쓰냐에 따라서 블락되거나 어려울 수 있음
- 인스타그램
- 빨리 접속하면 블락하고, 규칙을 랜덤하게 바꿈
- 전문 크롤링 업체를 쓰는 게 나음
- 인스타그램
- 일반적으로 사이트의 주소가 명시적으로 있는지에 따라서 보려고 함
- 개발자 도구를 통해서 많이 찾아낼 수 있음
- 셀레니움을 통해서 브라우저 자체를 코드 제어함 (속도는 느리다)
- 개발자 도구를 통해서 많이 찾아낼 수 있음
내부적인 기능들을 찾아서 눈치것 해야함
- 숨겨져 있는 주소를 찾아야함 → 개발자 도구에서 네트워크 쪽을 열심히 뒤져야함
- 대상 사이트가 일반적인 웹사이트라면? → html에서 내가 원하는 정보가 어디인지 찾기 ⇒ bs4의 BeautifulSoup 사용하면 됨 ⇒ 슾 블락 된다면 셀레니움 사용 ⇒⇒ 셀리니움 + 코드 사용
전자공시 사이트 → 날짜에 대한 공시정보를 추출

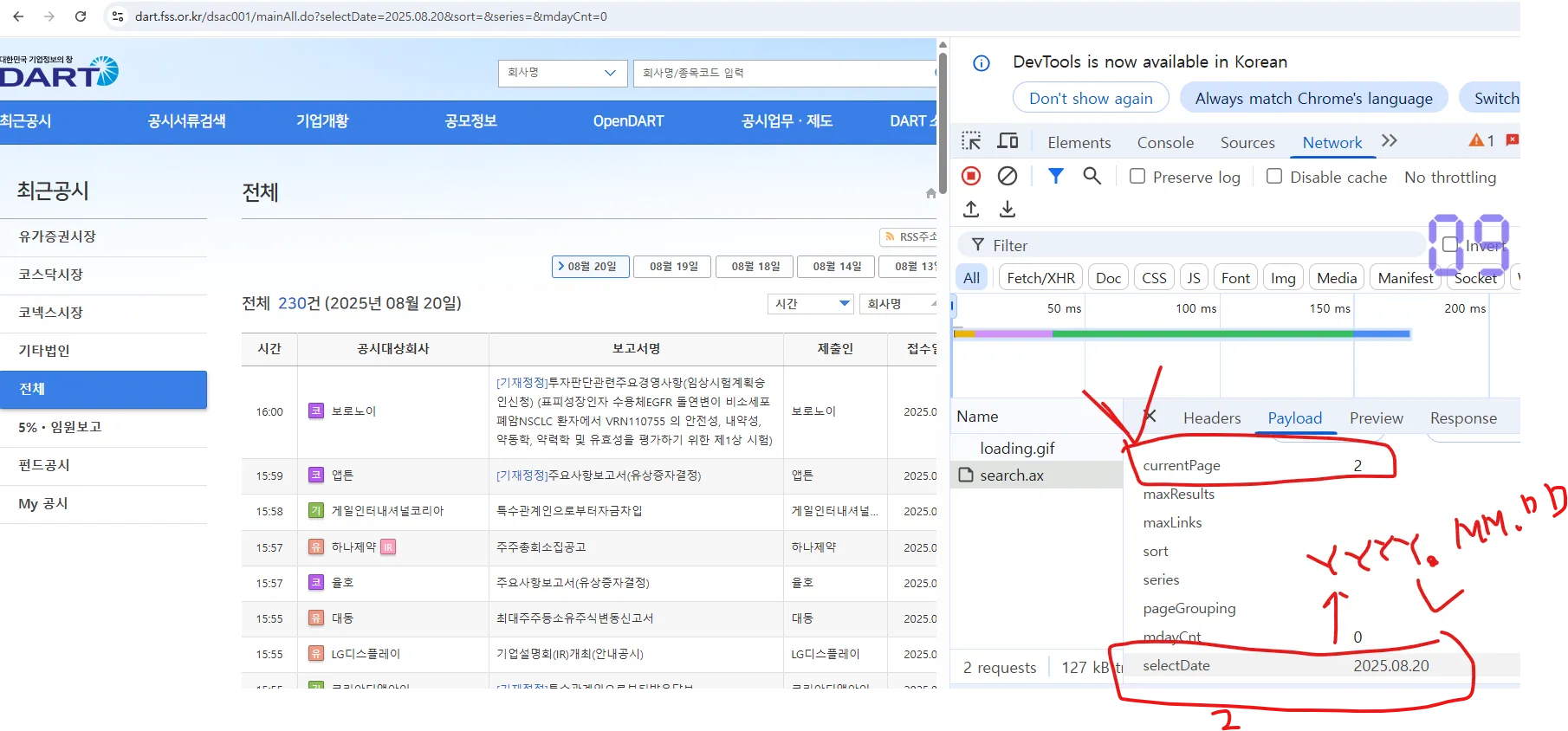
- Dart 사이트에서 주소 이리 저리 탐색을 해서 눈치껏 해야함
- https://dart.fss.or.kr/dsac001/mainAll.do?
- selectDate=2025.08.19&sort=&series=&mdayCnt=0¤tPage=2
- 내가 필요한 인터페이스
- selectDate : YYYY.MM.DD
- currentPage : 숫자( 원하는 페이지 숫자 )
- 내가 필요한 인터페이스
참고) 편의상 적당히 있는 날짜로 세팅 : 2025.02.24일로 선정
# 필요한 패키지
# 1) 통신 : urllib, requests etc
import requests
# 2) 일반적인 사이트 내용 : html --> ml : Tag 중심의 언어
# html에서도 원하는 정보를 추출할 때 tag 지원해주는 bs4
from bs4 import BeautifulSoup
# 3) 데이터 정리
import pandas as pd
# 4) ++++ 데이터를 처리하는 과정에서 : 정규식,,. 시간,,, etc
import re
import time
#예시 날짜: 2025.02.24
#==> 769건
#1페이지~8페이지
date = "2025.02.24"
page = 1
url = f'<https://dart.fss.or.kr/dsac001/mainAll.do?selectDate={date}&sort=&series=&mdayCnt=0¤tPage={page}>'
url
#==> 원하는 날짜의 원하는 페이지에 정밀 접근하는 주소가 완성됨
##'<https://dart.fss.or.kr/dsac001/mainAll.do?selectDate=2025.02.24&sort=&series=&mdayCnt=0¤tPage=1>'
#주소가 완성이 되었으니 -> 직접 html 통신을 해서 쓰면 된다
# ==> 어제는 FM적으로 params ~ 이런식으로 함
# 오늘은 간단하게 쓰겠다
res = requests.get(url)
res
##
참고) requests 패키지를 통해서 받은 정보를 열어보는 방식 2가지
- res.text
- 알아서 자기가 인코딩/디코딩 처리를 함
- 특별하게 인/디코딩에 대해서 신경쓸 필요가 없음
- res.content
- 이미지/동영상 ⇒ 바이트 값으로 직접 받는 경우
-
- res.json()
- json 패키지 없이도, 알아서 파이썬의 자료형으로 변경
⇒ 일반적인 사이트 : res.text 특별한 이미지/ 동영상 : res.content + api이나, 사이트 내부 api etc json : .json()
res.text

# ==> 페이지 소스 코드에 대한 문자열을 tag중심으로 접근할 수 있도록 파싱!!
# BeautifulSoup 그 역할을 함.
# + 어제 처리 대상 : xml ---> xml
# + 오늘 처리 대상 : html --> html.parser
soup = BeautifulSoup(res.text,"html.parser")
soup # ===> Tag 중심으로 정보 접근이 가능한 대상!!!!

참고) 페이지 전체에 대한 정보가 soup 변수에 담겨있음 + tag 중심으로 정보 접근이 용이한 상태
- ⇒ find(태그), find_all(태그)
- xml : 테그만으로도 충
- html: 테그 + 속성 접근
len(soup.find_all("div"))
#59
#방법1) dict를 활용해서 tag 이외에 속성 + 속성값으로 접근
soup.find_all("div",{"class":"headTitle"})
#[<div class="headTitle">
#<h3 id="subTitle"></h3>
#<ul class="navy" id="path">
#</ul>
#</div>]
#방법2) tagd의 속성도 다 정의가 되어있음
# => bs4에서도 만들어 두었습니다
soup.find_all("div",class_="headTitle")
#[<div class="headTitle">
#<h3 id="subTitle"></h3>
#<ul class="navy" id="path">
#</ul>
#</div
Q) 전체 그 날의 공시 자료의 수 체크!!!
- 내가 몇 페이지를 롤링할지 알 수 있겠죠!!

temp = soup.find_all("div", {"class":"pageInfo"})[0].text
temp
#[1/8] [총 769건]
# ++ 일반적인 웹사이트에서 필요한 정보들을 추출할 때 :대상이 문자열 -> 규칙(정규식)
# ==> 정규식에 따라서 패턴을 찾을 때 : re.findall(패턴, 어디서)
# ==> 정규식에 따라서 무엇을 무엇으로 변경 : re.sub(패턴, 무엇으로 변경, 어디서)
# try1) 찾을 패턴/규칙 : 숫자들 (1자 + 2자 + ..)+ 건
re.findall(r'\\d+', temp)
#['1', '8', '769']
re.findall(r'\\d+건', temp)#좀 더 정밀
#['769건']
temp = re.findall(r'\\d+건', temp)[0]
temp
#769건
re.sub(r'건','', temp)
#769
temp = re.sub(r'건', '', temp) # '769'
temp
#769
#==> 위의 temp에 해당하는 정보를 1페이지에 100개의 공시만 준다면
# 몇 페이지를 롤링할 것인가?
# 100으로 나눠서..-> 몫(올림처리)
# 100 -> 1페이지에 모두 담을 수 있음 -> 100//100 =1
# 101 -> 2페이지에 담아야함 -> 101//100 ==1.xxxx=> 올림해서 2로 만들어야함
if int(temp) % 100 ==0:
tot_page = int(temp) // 100
else:
tot_page = int(page) // 100 +1
tot_page
#1
정규식에서 사용될 때 특수문자 처리
- 정규식의 규칙을 서술하는데 사용되는 문자 vs 특수문자
- 파이썬 계열 : 특수문자 표현 \\
temp = soup.find_all("div", {"class":"pageInfo"})[0].text
temp
#[1/8] [총 769건]
re.findall(r'\\d+',temp)[1]
#**8**
re.findall(r'[0-9]+',temp)[1]
****#8
****re.findall(r'\\/\\d+\\]',temp)
#['/8]']
temp = re.findall(r'\\/\\d+\\]',temp)[0]
temp
#/8]
#지우기 : /, ]
re.sub(r'\\/|\\]',"",temp)
#8
temp = re.sub(r'\\/|\\]',"",temp) #이런 건 헷갈리면 지피티한테 물어보면 잘 알려줌
temp
#
참고) table → (tbody) → tr → td
#6
len(soup.find_all("tr"))
#101
# ==> 집중 대상은 tbody에 있는 실제 공시 tr 중심 --> 수집 샘플
# 최대한 타이트하게 접근
len(soup.find("tbody").find_all("tr"))
#100
# Q1) 1번 공시에 대한 정보만 가지고 와보자
soup.find("tbody").find_all("tr")
'''
[<tr>
<td>
18:36
</td>
<td class="tL">
<span class="innerWrap">
<span class="tagCom_kosdaq" style="cursor:default" title="코스닥시장">코</span>
<a href="javascript:openCorpInfoNew('01098792', 'winCorpInfo', '/dsae001/selectPopup.ax');" title="본느 기업개황 새창">
본느
</a>
</span>
</td>
<td class="tL">
<a href="/dsaf001/main.do?rcpNo=20250224901216" id="r_20250224901216" onclick="openReportViewer('20250224901216'); return false;" title="주주총회소집결의 공시뷰어 새창">주주총회소집결의
</a>
</td>
<td class="tL ellipsis" title="본느">본느</td>
<td>2025.02.24</td>
<td><span class="tagCom_kosdaq_other" style="cursor:default" title="본 공시사항은 한국거래소 코스닥시장본부 소관임">코</span><span class="tagCom_jung_other" style="cursor:default" title="본 보고서 제출 후 정정신고가 있으니 관련 보고서를 참조하시기 바람">정</span></td>
</tr>,
<tr>
<td>
18:33
</td>
<td class="tL">
<span class="innerWrap">
<span class="tagCom_kosdaq" style="cursor:default" title="코스닥시장">코</span>
<a href="javascript:openCorpInfoNew('00611736', 'winCorpInfo', '/dsae001/selectPopup.ax');" title="엑시콘 기업개황 새창">
엑시콘
</a>
</span>
</td>
<td class="tL">
<a href="/dsaf001/main.do?rcpNo=20250224901214" id="r_20250224901214" onclick="openReportViewer('20250224901214'); return false;" title="주주총회소집결의 공시뷰어 새창">주주총회소집결의
</a>
</td>
<td class="tL ellipsis" title="엑시콘">엑시콘</td>
<td>2025.02.24</td>
<td><span class="tagCom_kosdaq_other" style="cursor:default" title="본 공시사항은 한국거래소 코스닥시장본부 소관임">코</span><span class="tagCom_jung_other" style="cursor:default" title="본 보고서 제출 후 정정신고가 있으니 관련 보고서를 참조하시기 바람">정</span></td>
</tr>,
<tr>
<td>
18:20
</td>
<td class="tL">
<span class="innerWrap">
<span class="tagCom_kospi" style="cursor:default" title="유가증권시장">유</span>
<a href="javascript:openCorpInfoNew('00161116', 'winCorpInfo', '/dsae001/selectPopup.ax');" title="HL D&I 기업개황 새창">
HL D&I
</a>
</span>
</td>
<td class="tL">
<a href="/dsaf001/main.do?rcpNo=20250224801206" id="r_20250224801206" onclick="openReportViewer('20250224801206'); return false;" title="연결재무제표기준영업(잠정)실적(공정공시) 공시뷰어 새창"><span class="txtCB" title="본 보고서명으로 이미 제출된 보고서의 기재내용이 변경되어 제출된 것임">[기재정정]</span>연결재무제표기준영업(잠정)실적(공정공시)
</a>
</td>
<td class="tL ellipsis" title="HL D&I">HL D&I</td>
<td>2025.02.24</td>
<td><span class="tagCom_kospi_other" style="cursor:default" title="본 공시사항은 한국거래소 유가증권시장본부 소관임">유</span></td>
</tr>,
<tr>
<td>
18:15
</td>
'''
# - 처음 공시에 대한 제출 시간 출력
temp.find_all("td")[0].text
'''\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t18:36\\r\\n\\t\\t\\t\\t\\t\\t\\t'''
참고) 내가 원하는 정보가 있지만... 하다보면 눈에 안 보이는 공백이 있음
⇒ 공백을 제거해야함
- sol1) .strip()
- 양쪽에 대한 공백을 제거해주는 역할 ⇒ 중간에 공백이 있다면 어떡해? 걍 노답임 → " 18:36 " --> .strip() --> "18:36" → " 18: 36 " --> .strip() --> "18: 36"
t_str1 = "\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t18:36\\r\\n\\t\\t\\t\\t\\t\\t\\t"
t_str1
'''
\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t18:36\\r\\n\\t\\t\\t\\t\\t\\t\\t
'''
print(t_str1)
'''
18:36
'''
t_str1.strip()
'''
18:36
'''
#중간에 공백 있는 경우
t_str2 = "\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t18:\\t\\t\\t\\r\\n\\t36\\r\\n\\t\\t\\t\\t\\t\\t\\t"
t_str2
'''\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t18:\\t\\t\\t\\r\\n\\t36\\r\\n\\t\\t\\t\\t\\t\\t\\t'''
print(t_str2)
'''
18:
36
'''
t_str2.strip()
'''
18:\\t\\t\\t\\r\\n\\t36
'''
re.sub( r"\\r|\\n|\\t|\\s", "", t_str2)
# --> 공백에 대한 것들을 처리할 수 있음...
'''
18:36
'''
# --> 처음 공시 시간
temp.find_all("td")[0].text.strip()
'''
18:36
''
- 처음 공시한 회사가 속한 시장/카테고리
- 처음 공시한 회사의 코드값(DART에서 관리하는)
- 처음 공시한 회사의 이름
- 기존과 다른 점
- 내가 원하는 정보가 tag에 쌓여있는 값으로도 있지만
- find/find_all
- tag의 속성에 값으로도 존재
- get(속성이름)
- 기존과 다른 점
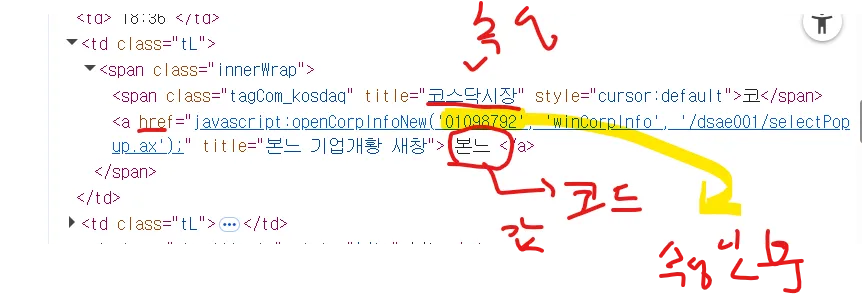
temp.find_all("td")[1].find_all("span")[1]
'''
<span class="tagCom_kosdaq" style="cursor:default" title="코스닥시장">코</span>
'''
temp.find_all("td")[1].find_all("span")[1].text
'''
코
'''
#회사가 속한 시장
temp.find_all("td")[1].find_all("span")[1].get("title")
'''
코스닥시장
'''
temp.find_all("td")[1].text.strip()
'''
코\\n\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t본느
'''
temp.find_all("td")[1].text[6:].strip()
'''
본느
'''
temp.find_all("td")[1].find('a').text.strip()
# --> 회사 이름 추출
'''
본느
'''
temp.find_all("td")[1].find('a')
'''
<a href="javascript:openCorpInfoNew('01098792', 'winCorpInfo', '/dsae001/selectPopup.ax');" title="본느 기업개황 새창">
본느
</a>
'''
temp.find_all("td")[1].find('a').get("href")
# 0 --> 주긴 했는데 원하는 값을 추출
# ==> 규칙 : 숫자 (0-9) 연속 8자리 ==> [0-9]{8}, \\d{8}
'''
javascript:openCorpInfoNew('01098792', 'winCorpInfo', '/dsae001/selectPopup.ax');
'''
re.findall(r'[0-9]+', temp.find_all("td")[1].find('a').get("href"))
'''
['01098792', '001']
'''
re.findall(r'[0-9]{8}', temp.find_all("td")[1].find('a').get("href"))
#[0-9]{8} : 0부터 9까지 있는 거 8개 이어져있는 거 찾아달라
'''
['01098792']
'''
re.findall(r'[0-9]{8}', temp.find_all("td")[1].find('a').get("href"))[0]
'''
01098792
'''
처음 공시의 실제 내용
- 공시제목
- 공시의 고유값

temp.find_all("td")[2]
'''
<td class="tL">
<a href="/dsaf001/main.do?rcpNo=20250224901216" id="r_20250224901216" onclick="openReportViewer('20250224901216'); return false;" title="주주총회소집결의 공시뷰어 새창">주주총회소집결의
</a>
</td>
'''
temp.find_all("td")[2].text.strip()
'''
주주총회소집결의
'''
temp.find_all("td")[2].get("href") #아무 반응 없음
#왜? td 안에 href 없거든
temp.find_all("td")[2].find("a").get("href") #원하는 속성에 대한 tag에서
#/dsaf001/main.do?rcpNo=20250224901216
# 규칙 : 숫자 연속 14자리
# ==> [0-9]{14}, \\d{14}
re.findall(r'\\d{14}', temp.find_all("td")[2].find("a").get("href"))[0]
#20250224901216
temp.find_all("td")[2].find("a").get("id")[2:]
#20250224901216
# - 처음 공시에 대한 접수일자
temp.find_all("td")[4].text
#2025.02.24
idx =0
temp = soup.find("tbody").find_all("tr")[idx]
print( temp.find_all("td")[0].text.strip() )
print( temp.find_all("td")[1].find_all("span")[1].get("title") )
print( temp.find_all("td")[1].find("a").text.strip() )
print( re.findall( r'\\d{8}', temp.find_all("td")[1].find("a").get("href") )[0] )
print( temp.find_all("td")[2].text.strip() )
print( re.findall( r'\\d{14}', temp.find_all("td")[2].find("a").get("href"))[0] )
print( temp.find_all("td")[4].text )
print("*"*60)
idx =1
temp = soup.find("tbody").find_all("tr")[idx]
print( temp.find_all("td")[0].text.strip() )
print( temp.find_all("td")[1].find_all("span")[1].get("title") )
print( temp.find_all("td")[1].find("a").text.strip() )
print( re.findall( r'\\d{8}', temp.find_all("td")[1].find("a").get("href") )[0] )
print( temp.find_all("td")[2].text.strip() )
print( re.findall( r'\\d{14}', temp.find_all("td")[2].find("a").get("href"))[0] )
print( temp.find_all("td")[4].text )
print("*"*60)
'''
18:36
코스닥시장
본느
01098792
주주총회소집결의
20250224901216
2025.02.24
************************************************************
18:33
코스닥시장
엑시콘
00611736
주주총회소집결의
20250224901214
2025.02.24
************************************************************
'''
page_cnt = len(soup.find("tbody").find_all("tr"))
#모든 페이지가 100개라고 장담 못 하니까
for idx in range( page_cnt):
temp = soup.find("tbody").find_all("tr")[idx]
print( temp.find_all("td")[0].text.strip() )
print( temp.find_all("td")[1].find_all("span")[1].get("title") )
print( temp.find_all("td")[1].find("a").text.strip() )
print( re.findall( r'\\d{8}', temp.find_all("td")[1].find("a").get("href") )[0] )
print( temp.find_all("td")[2].text.strip() )
print( re.findall( r'\\d{14}', temp.find_all("td")[2].find("a").get("href"))[0] )
print( temp.find_all("td")[4].text )
print("*"*60)
'''
18:36
코스닥시장
본느
01098792
주주총회소집결의
20250224901216
2025.02.24
************************************************************
18:33
코스닥시장
엑시콘
00611736
주주총회소집결의
20250224901214
2025.02.24
************************************************************
18:20
유가증권시장
HL D&I
00161116
[기재정정]연결재무제표기준영업(잠정)실적(공정공시)
20250224801206
2025.02.24
************************************************************
18:15
유가증권시장
SK
00181712
증권신고서(채무증권)
20250224004812
2025.02.24
************************************************************
18:11
코스닥시장
큐에스아이
00411446
주주총회소집결의
20250224901133
2025.02.24
************************************************************
18:10
코스닥시장
큐에스아이
00411446
현금ㆍ현물배당결정
20250224901185
2025.02.24
************************************************************
.........
'''
# page_cnt = len(soup.find("tbody").find_all("tr"))
# for idx in range( page_cnt):
for idx, temp in enumerate(soup.find("tbody").find_all("tr")):
# temp = soup.find("tbody").find_all("tr")[idx]
print( temp.find_all("td")[0].text.strip() )
print( temp.find_all("td")[1].find_all("span")[1].get("title") )
print( temp.find_all("td")[1].find("a").text.strip() )
print( re.findall( r'\\d{8}', temp.find_all("td")[1].find("a").get("href") )[0] )
print( temp.find_all("td")[2].text.strip() )
print( re.findall( r'\\d{14}', temp.find_all("td")[2].find("a").get("href"))[0] )
print( temp.find_all("td")[4].text )
print("*"*60)
print("Done!")
#얘를 DF에 넣어보자
dart_tot=[]
for idx, temp in enumerate(soup.find("tbody").find_all("tr")):
d_time = temp.find_all("td")[0].text.strip()
d_market = temp.find_all("td")[1].find_all("span")[1].get("title")
d_co_name = temp.find_all("td")[1].find("a").text.strip()
d_co_id = re.findall( r'\\d{8}', temp.find_all("td")[1].find("a").get("href") )[0]
d_rcp_name = temp.find_all("td")[2].text.strip()
d_rcp_no = re.findall( r'\\d{14}', temp.find_all("td")[2].find("a").get("href"))[0]
d_date = temp.find_all("td")[4].text
# ==> 출력이 되는지 ㅌ체크 후에 출력 대시 변수화하기 (위 셀에서 출력 했었음 )
dart_tot.append([d_time,d_market,d_co_name,d_co_id,d_rcp_name,d_rcp_no,d_date])
print("*"*60)
print("Done!")
pd.DataFrame(dart_tot)

df_1 = pd.DataFrame(
data = dart_tot,
columns = [d_time,d_market,d_co_name,d_co_id,d_rcp_name,d_rcp_no,d_date]
)
df_1

df_1.to_csv("2025_02_21.csv", sep=",")
2025년 2월 24일 전체 모든 공시 받아보기
- for
- 2024 2월 24일 1페이지 ~ 8페이지까지 롤링
- 그 날짜의 그 페이지를 요청하는 주소
- 직접 요청 → 받아와서 → 처리하기 편한 soup 변환
- ⇒ 그 페이지에 있는 모든 공시들을 돌아가면서 for → 처리한 공시 정보들을 쌓으면 끝
- 편하게 하기 위해서
- 날짜별로 돌려가면서 몇 페이지가 끝인지 모르니
- 중간에 값이 없거나, 공시정보가 없으면 그만 → 다음 날짜
- while True: 페이지 넘버 : 1부터 +1 if 요청 사항에 대한 정보/공시 없다면 break
# 1) 그 날에 돌릴 페이지 체크!!!
date = "2025.02.24" # <--- 이 날은 무조건 있다고 가정하고,,,,,,,
page = "1"
url = f'<https://dart.fss.or.kr/dsac001/mainAll.do?selectDate={date}&sort=&series=&mdayCnt=0¤tPage={page}>'
res = requests.get( url )
soup = BeautifulSoup( res.text, "html.parser")
tot_page = soup.find_all("div",{"class":"pageInfo"})[0].text
tot_page = re.findall( r'\\/\\d+\\]', tot_page)[0]
tot_page = re.sub( r'\\/|\\]',"", tot_page)
tot_page = int(tot_page)
# ---> 그날의 돌릴 페이지 계산!!
# 2) 전체 페이지를 담을 정보
dart_tot = []
# ===> 너무 많이 담으면 중간 중간 잘라서 저장
# 3) 1번에서 계산된 tot_page를 돌아가면 됨
for page in range(1, tot_page+1):
# 1번 페이지는 한 번 더 쏘고 진행함
url = f'<https://dart.fss.or.kr/dsac001/mainAll.do?selectDate={date}&sort=&series=&mdayCnt=0¤tPage={page}>'
res = requests.get( url )
soup = BeautifulSoup( res.text, "html.parser")
#이제는 i번째 페이지의 개별 공시 정보들을 돌려가면서 추출
# ==> dart_tot 추가!
for idx, temp in enumerate( soup.find("tbody").find_all("tr")):
d_time = temp.find_all("td")[0].text.strip()
d_market = temp.find_all("td")[1].find_all("span")[1].get("title")
d_co_name = temp.find_all("td")[1].find("a").text.strip()
d_co_id = re.findall( r'\\d{8}', temp.find_all("td")[1].find("a").get("href") )[0]
d_rcp_name = temp.find_all("td")[2].text.strip()
d_rcp_no = re.findall( r'\\d{14}', temp.find_all("td")[2].find("a").get("href"))[0]
d_date = temp.find_all("td")[4].text
# ==> 출력이 되는지 체크 후에,,,출력 대신에 변수화!!!
dart_tot.append([d_time, d_market, d_co_name,d_co_id,d_rcp_name,d_rcp_no,d_date])
print(f"{page}페이지 공시 정보 처리 완료!")
# +++ 시간 지연에 대한 추가 처리가 필요할 수도 있음
print("Done!!!")
'''
1페이지 공시 정보 처리 완료!
2페이지 공시 정보 처리 완료!
3페이지 공시 정보 처리 완료!
4페이지 공시 정보 처리 완료!
5페이지 공시 정보 처리 완료!
6페이지 공시 정보 처리 완료!
7페이지 공시 정보 처리 완료!
8페이지 공시 정보 처리 완료!
Done!!!
'''
len(dart_tot)
#769
df_2 = pd.DataFrame(
data = dart_tot,
columns = ["time","market","co_name","co_id","rcp_name","rcp_id","req_date"]
)
df_2

df_2.head()

df_2.tail()

'데이터분석 > Pandas' 카테고리의 다른 글
| [Python] Pandas 10 _ csv (0) | 2025.08.21 |
|---|---|
| [Python] Pandas 09 _ daum_site (2) | 2025.08.21 |
| [Python] Pandas 07 _ json_kobis_api (2) | 2025.08.20 |
| [Python] Pandas 06 _ kobis_api_xml (0) | 2025.08.20 |
| [Python] pandas 05_kobis_api_json (0) | 2025.08.19 |