내가 원하는 정보/데이터가 웹 상에 존재할 때
- API 형태로 정보를 제공할 때
- JSON으로 제공
- json 패키지 → 파이썬 리스트/dict 자료형 변환 → 정수 인덱스, 키값 중심 : 순차 접근 ⇒ pandas의 DataFrame과 상호호환이 용이함!!!
- XML 으로 제공
- BeautifulSoup 패키지(bs4) : Tag 중심의 숏컷
- JSON으로 제공
- 그냥 웹 사이트에 존재 (사람인 vs 잡코리아 크롤링에 대한 소송~~근데 구글도 다 함)
- 정적인 사이트
- 주소가 원하는 대로 바뀜 (크롤링하기 아주 편함)
- 원하는 정보의 사이트가 주소가 안 보이거나, 내부에서 호출하거나 (여러 케이스가 있음) → case by case → 숨겨진 정보들을 찾아보자 ⇒ 동적으로 움직이는 것 중에서 → 셀레니움 → 브라우저를 통제 (이것마저 블락하는 경우도 있음)
- 정적인 사이트
내가 원하는 정보/데이터가 주어진 파일로 존재할 떄 ⇒ pandas 계열에서 다양한 파일들을 DF으로 불러들이는 것을 만들어 둠!!
기준 사이트 페이지 : kobis api --> 영화 목록
https://www.kobis.or.kr/kobisopenapi/homepg/apiservice/searchServiceInfo.do
영화진흥위원회 오픈API
제공서비스 영화관입장권통합전산망이 제공하는 오픈API서비스 모음입니다. 사용 가능한 서비스를 확인하고 서비스별 인터페이스 정보를 조회합니다.
www.kobis.or.kr
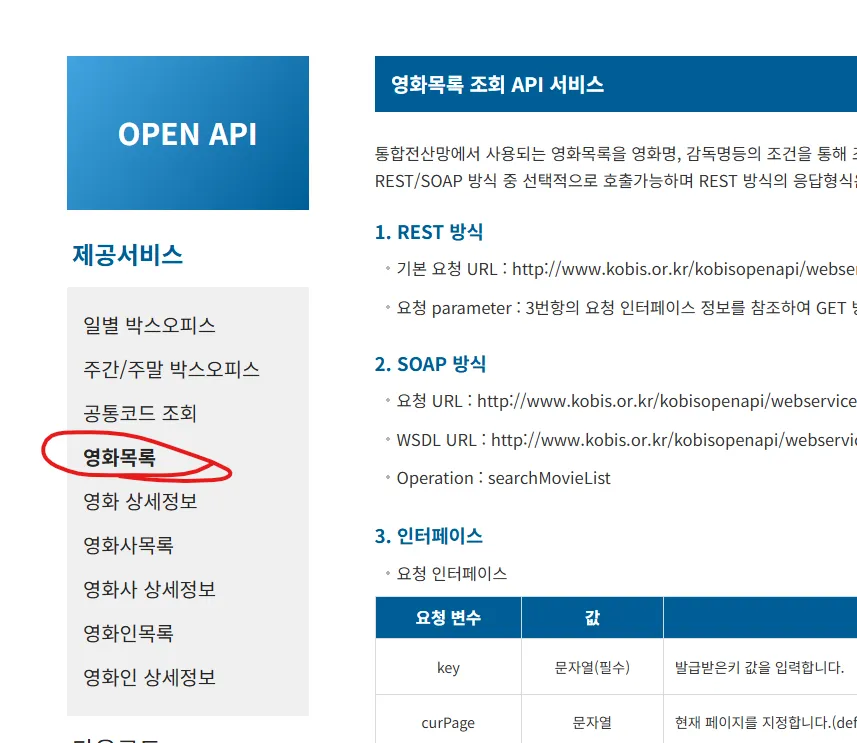
실습 목적
- 영화관련 정보들을 처리하려고 함!!
- 영화 관련 정보들이 모여있는 사이트!!
- 운이 좋게도 ,. api를 운영하고 있더라!!!
- 나는 최신 영화의 간략한 정보들 수집!!! (영화코드, 제목, 영문제목, 장르, 개봉일 etc) ( +++ 상세 정보 : 배우, 스탭수, 세부 장르~~~)
- 내가 원하는 정보가 어디에 있는지 체크
- api 매뉴얼/사이트 정보
- 직접 찾아가면서 체크해야함
- 영화목록요청 api에 있었다
- api 매뉴얼/사이트 정보
- 내가 좀 더 구체적으로 요청할 수 있는 사항들이 있는지 체크 (요청 인터페이스 쪽을 체크!!!)
⇒ 지금 시점의 최신 영화 목록을 요청하려고 함
- 한 번에 50개 정도를 요청하고 싶다!

- 메뉴얼 요청인터페이스 : item
⇒ 기본 작성 항목 : key + 요청할 사항 추가
- 파라미터에 값을 넣어서 전달하는 방식 (get 방식) → url 직접 작성
- 기본 url ? 파라미터=
&파라미터2= - http://kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.**json**?key=84f5fd2eb892d013291cc10dcba3f787&itemPerPage=50 → 요청하려는 사항에 맞는 정확한 주소인지를 체크
- 기본 url ? 파라미터=
- 코드 상에서 http 통신 ⇒ kobis api 서버에 2번 요청사항을 보내야함
- http통신 파이썬 패키지 : urllib, requests etc
- ++ 요청하려는 상황에 대한 주소를 기록해서 보내면 됨!!!
- 요청해서 받은 정보 JSON을 편하게 접근하기 위해서 json 패키지 사용
- 접근 : 정수인덱스, 키값
- pandas의 DataFrame에 잘 담아두겠습니다
#필요한 패키지
import pandas as pd
import urllib.request # 파이썬에 있는 대표적인 http 통신용 패키지 중 하나
import json # <- json 양식에 맞는 문자열 데이터 --> 파이썬 list/dict 변환
#++정규식, 날짜 등
Step1) 내가 필요한 정보들을 요청할 주소 생성!!
- 매뉴얼을 보면서 .. 웹 브라우저 test
- get 방식 : 주소에 직접 요청할 사항들을 다 기록해서 전달
- baseurl?요청파라미터=요청할값&요청파라미터2=요청할값2&~~~
# 기본 주소 : json으로 주세요~~
url_p1 = " <http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json>"
# 필수항목 : key
key = "84f5fd2eb892d013291cc10dcba3f787" # <--- 본인 key사용하면 됨
# +++ option) itemPerPage ==> 50개 요청!!!
url_p2 = "50"
# ===> 위의 요청사항을 기반으로 요청할 url을 완성!!!!
url = url_p1 + "?key=" + key + "&itemPerPage=" + url_p2
url
# <http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json?key=84f5fd2eb892d013291cc10dcba3f787&itemPerPage=50>
# *** 주의사항 *** 50개를 요청한다고,,,,,꼭 50개가 온다는 보장은 없음!!!
# ==> 항상 받고나서 체크해야함!!!
- 메뉴얼 요청인터페이스 : item
⇒ 기본 작성 항목 : key + 요청할 사항 추가
- 파라미터에 값을 넣어서 전달하는 방식 (get 방식) → url 직접 작성
- 기본 url ? 파라미터=
&파라미터2= - http://kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.**json**?key=84f5fd2eb892d013291cc10dcba3f787&itemPerPage=50 → 요청하려는 사항에 맞는 정확한 주소인지를 체크
- 기본 url ? 파라미터=
- 코드 상에서 http 통신 ⇒ kobis api 서버에 2번 요청사항을 보내야함
- http통신 파이썬 패키지 : urllib, requests etc
- ++ 요청하려는 상황에 대한 주소를 기록해서 보내면 됨!!!
- 요청해서 받은 정보 JSON을 편하게 접근하기 위해서 json 패키지 사용
- 접근 : 정수인덱스, 키값
- pandas의 DataFrame에 잘 담아두겠습니다
#필요한 패키지
import pandas as pd
import urllib.request # 파이썬에 있는 대표적인 http 통신용 패키지 중 하나
import json # <- json 양식에 맞는 문자열 데이터 --> 파이썬 list/dict 변환
#++정규식, 날짜 등
Step1) 내가 필요한 정보들을 요청할 주소 생성!!
- 매뉴얼을 보면서 .. 웹 브라우저 test
- get 방식 : 주소에 직접 요청할 사항들을 다 기록해서 전달
- baseurl?요청파라미터=요청할값&요청파라미터2=요청할값2&~~~
# 기본 주소 : json으로 주세요~~
url_p1 = " <http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json>"
# 필수항목 : key
key = "84f5fd2eb892d013291cc10dcba3f787" # <--- 본인 key사용하면 됨
# +++ option) itemPerPage ==> 50개 요청!!!
url_p2 = "50"
# ===> 위의 요청사항을 기반으로 요청할 url을 완성!!!!
url = url_p1 + "?key=" + key + "&itemPerPage=" + url_p2
url
# <http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json?key=84f5fd2eb892d013291cc10dcba3f787&itemPerPage=50>
# *** 주의사항 *** 50개를 요청한다고,,,,,꼭 50개가 온다는 보장은 없음!!!
# ==> 항상 받고나서 체크해야함!!!
type(movie_data)
#dict
movie_data.keys()
#dict_keys(['movieListResult'])type(movie_data)
#dict
movie_data.keys()
#dict_keys(['movieListResult'])
movie_data["movieListResult"]
type(movie_data["movieListResult"])
#dict
movie_data["movieListResult"].keys()
#dict_keys(['totCnt', 'source', 'movieList'])
type(movie_data["movieListResult"]["movieList"])
#list
# --> 내가 요청해서 받은 영화 정보 중에서 처음 영화에 대한 정보
movie_data["movieListResult"]["movieList"][0]
#{'movieCd': '2025A733',
#'movieNm': '울 엄마는 마피아',
#'movieNmEn': 'Mafia Mamma',
#'prdtYear': '2023',
#'openDt': '',
#'typeNm': '장편',
#'prdtStatNm': '기타',
#'nationAlt': '영국',
#'genreAlt': '코미디,액션',
#'repNationNm': '영국',
#'repGenreNm': '코미디',
#'directors': [{'peopleNm': '캐서린 하드윅'}],
#'companys': []}
#본인이 요청한 영화정보에 대한 결과를 가지고
# Q-1) 1번 영화에 대한 정보 덩어리를 출력해보세요
m1 = movie_data["movieListResult"]["movieList"][0]
m1
#{'movieCd': '2025A733',
#'movieNm': '울 엄마는 마피아',
#'movieNmEn': 'Mafia Mamma',
#'prdtYear': '2023',
#'openDt': '',
#'typeNm': '장편',
#'prdtStatNm': '기타',
#'nationAlt': '영국',
#'genreAlt': '코미디,액션',
#'repNationNm': '영국',
#'repGenreNm': '코미디',
#'directors': [{'peopleNm': '캐서린 하드윅'}],
#'companys': []}
# Q-2) 1번 영화의 영화코드값을 출력해보세요
#movie_data["movieListResult"]["movieList"][0]['movieCd']
m1['movieCd']
#2025A733
# Q-3) 1번 영화의 제목(국문)을 출력해보세요
#movie_data["movieListResult"]["movieList"][0]['movieNm']
m1['movieNm']
#울 엄마는 마피아
# Q-4) 1번 영화의 제목 (영문)을 출력해보세요
#movie_data["movieListResult"]["movieList"][0]['movieNmEn']
m1['movieNmEn']
#Mafia Mamma
# Q-5) 1번 영화의 개봉일을 출력해보세요
#movie_data["movieListResult"]["movieList"][0]['openDt']
m1['openDt']
#''
# Q-6) 1번 영화의 감독에 대한 정보가 있다면/ 처음 나온 감독의 이름만 출력해보세요
#movie_data["movieListResult"]["movieList"][0]['directors'][0]['peopleNm']
m1['directors'][0]['peopleNm']
#'캐서린 하드윅'
# Q-7) 하다가 에러가 발생한다면 어떻게 해야할까
# ===> 1번 영화에 대한 위의 코드~~감독까지 출력!!
# ===> 2번 영화에 대한 위의 코드~~감독까지 출력!!
# ===> 3번 영화에 대한 위의 코드~~감독까지 출력!!
# ... 규칙이 보인다!!!!
# 1번
print(movie_data["movieListResult"]["movieList"][0]["movieCd"])
print(movie_data["movieListResult"]["movieList"][0]["movieNm"])
print(movie_data["movieListResult"]["movieList"][0]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][0]["openDt"])
print(movie_data["movieListResult"]["movieList"][0]["directors"][0]["peopleNm"])
# 2번
print(movie_data["movieListResult"]["movieList"][1]["movieCd"])
print(movie_data["movieListResult"]["movieList"][1]["movieNm"])
print(movie_data["movieListResult"]["movieList"][1]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][1]["openDt"])
print(movie_data["movieListResult"]["movieList"][1]["directors"][0]["peopleNm"]) #오류남 왜? 밑에서 보자
if movie_data["movieListResult"]["movieList"][1]["directors"] == []:
print("감독이름 없음")
else:
print(movie_data["movieListResult"]["movieList"][1]["directors"][0]["peopleNm"])
#감독이름 없음
# 1번
print(movie_data["movieListResult"]["movieList"][0]["movieCd"])
print(movie_data["movieListResult"]["movieList"][0]["movieNm"])
print(movie_data["movieListResult"]["movieList"][0]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][0]["openDt"])
print(movie_data["movieListResult"]["movieList"][0]["directors"][0]["peopleNm"])
print("*"*50)
# 2번
print(movie_data["movieListResult"]["movieList"][1]["movieCd"])
print(movie_data["movieListResult"]["movieList"][1]["movieNm"])
print(movie_data["movieListResult"]["movieList"][1]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][1]["openDt"])
if movie_data["movieListResult"]["movieList"][1]["directors"] == []:
print("감독이름 없음")
else:
print(movie_data["movieListResult"]["movieList"][1]["directors"][0]["peopleNm"])
print("*"*50)
# 3번째 영화
print(movie_data["movieListResult"]["movieList"][2]["movieCd"])
print(movie_data["movieListResult"]["movieList"][2]["movieNm"])
print(movie_data["movieListResult"]["movieList"][2]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][2]["openDt"])
if movie_data["movieListResult"]["movieList"][2]["directors"] ==[]:
print("감독이름없음!!")
else:
print(movie_data["movieListResult"]["movieList"][2]["directors"][0]["peopleNm"])
#2025A733
#울 엄마는 마피아
#Mafia Mamma
#3
#캐서린 하드윅
#**************************************************
#20257127
#쉬운 여자 - 먼저 벌린 여친의 친구
#
#
#감독이름 없음
#**************************************************
#20257150
#음란한 옆집 미시 - 가랑이에서 들려온 야한 신음
#
#
#감독이름없음!!
# Q) 본인이 받은 50개 영화에 대해서 코드~~감독까지 다 출력해보세요!!!
# ==> for문 사용해서 롤링~~~ 필요한 값 0~49 : 영화갯수
tot_cnt = len(movie_data["movieListResult"]["movieList"])
for i in range(tot_cnt):
print(movie_data["movieListResult"]["movieList"][i]["movieCd"])
print(movie_data["movieListResult"]["movieList"][i]["movieNm"])
print(movie_data["movieListResult"]["movieList"][i]["movieNmEn"])
print(movie_data["movieListResult"]["movieList"][i]["openDt"])
if movie_data["movieListResult"]["movieList"][i]["directors"] ==[]:
print("감독이름없음!!")
else:
print(movie_data["movieListResult"]["movieList"][i]["directors"][0]["peopleNm"])
print("*"*50)
# 수정 : 데이터 수집/ 처리 ==> 1개 데이터/샘플 단위로!!!!!! ****
tot_cnt = len(movie_data["movieListResult"]["movieList"])
for i in range(tot_cnt):
# i번째 영화에 대한 정보 temp
temp = movie_data["movieListResult"]["movieList"][i]
print(temp["movieCd"])
print(temp["movieNm"])
print(temp["movieNmEn"])
print(temp["openDt"])
if temp["directors"] ==[]:
print("감독이름없음!!")
else:
print(temp["directors"][0]["peopleNm"])
print("*"*50)
- 위의 과정은 개별 영화에 대한 정보를 접근 & 출력을 하고 땡
- 개별 정보에 대한 접근이 규칙을 제대로 했는지 체크
-
- 에러 처리
- 이 정보를 담아두자
- DataFrame에 담아두자 → 좀 무거운 느낌이 있음 : 가볍게 필요한 정보들만 추려서 핸들링을 하자 (리스트, deque, dict 등…)
- 나중에는 한 번에 DF로 변경할 수도 있음
'''
tot_data= [
[ 2025A733, 울 엄마는 마피아 , 장편,],
[ 20257127, 쉬운 여자 - 먼저 벌린 여친의 친구, 장편],
[],...
]
#=> 2차원에 대한 유사 표현
# + dict, deque etc
tot_data = [
{"movieCd":2025A733, "title":"울 엄마는 마피아"},
{"movieCd":20257127, "title":"쉬운 여자 - 먼저 벌린 여친의 친구"},
....
]
# ==> DataFrame 변환이 용이함
'''
# tot_cnt = len(movie_data["movieListResult"]["movieList"])
for idx, data in enumerate(movie_data["movieListResult"]["movieList"]):
print(idx)
print(data)
print("*"*60)
'''
0
{'movieCd': '2025A733', 'movieNm': '울 엄마는 마피아', 'movieNmEn': 'Mafia Mamma', 'prdtYear': '2023', 'openDt': '', 'typeNm': '장편', 'prdtStatNm': '기타', 'nationAlt': '영국', 'genreAlt': '코미디,액션', 'repNationNm': '영국', 'repGenreNm': '코미디', 'directors': [{'peopleNm': '캐서린 하드윅'}], 'companys': []}
************************************************************
1
{'movieCd': '20257127', 'movieNm': '쉬운 여자 - 먼저 벌린 여친의 친구', 'movieNmEn': '', 'prdtYear': '2023', 'openDt': '', 'typeNm': '장편', 'prdtStatNm': '기타', 'nationAlt': '일본', 'genreAlt': '성인물(에로)', 'repNationNm': '일본', 'repGenreNm': '성인물(에로)', 'directors': [], 'companys': []}
************************************************************
2
{'movieCd': '20257150', 'movieNm': '음란한 옆집 미시 - 가랑이에서 들려온 야한 신음', 'movieNmEn': '', 'prdtYear': '2023', 'openDt': '', 'typeNm': '장편', 'prdtStatNm': '기타', 'nationAlt': '일본', 'genreAlt': '성인물(에로)', 'repNationNm': '일본', 'repGenreNm': '성인물(에로)', 'directors': [], 'companys': []}
************************************************************
3
{'movieCd': '20257151', 'movieNm': '유부녀 섹파 - 다시 벌려준 허벅지', 'movieNmEn': '', 'prdtYear': '2023', 'openDt': '', 'typeNm': '장편', 'prdtStatNm': '기타', 'nationAlt': '일본', 'genreAlt': '성인물(에로)', 'repNationNm': '일본', 'repGenreNm': '성인물(에로)', 'directors': [], 'companys': []}
************************************************************
4
{'movieCd': '20257152', 'movieNm': '젖은 변태녀 - 야근마다 벌어지는 가랑이', 'movieNmEn': '', 'prdtYear': '2023', 'openDt': '', 'typeNm': '장편', 'prdtStatNm': '기타', 'nationAlt': '일본', 'genreAlt': '성인물(에로)', 'repNationNm': '일본', 'repGenreNm': '성인물(에로)', 'directors': [], 'companys': []}
************************************************************
5
{'movieCd': '20249318', 'movieNm': '챌린저스', 'movieNmEn': 'Challengers', 'prdtYear': '2024', 'openDt': '20240424', 'typeNm': '장편', 'prdtStatNm': '개봉', 'nationAlt': '미국', 'genreAlt': '드라마,멜로/로맨스', 'repNationNm': '미국', 'repGenreNm': '드라마', 'directors': [{'peopleNm': '루카 구아다니노'}], 'companys': []}
************************************************************
......
'''
# 할 일 : 위의 정보들을 DF에 담아보자!!!
# ===> 방법1) list계열에서 처리하고자 함!!! ( deque)
# + 오/열 맞춰야 함!!!!!( 2차원 DF으로 변경!!)
tot_data = [] # --> 개별 원소를 리스트로 담아서, 전체를 리스트 포장 2D
for idx, data in enumerate(movie_data["movieListResult"]["movieList"]):
# data : 개별 영화 정보 dict
# idx : 정수 인덱스,,,
i_code = data["movieCd"]
i_name = data["movieNm"]
i_name_e = data["movieNmEn"]
i_day = data["openDt"]
if data["directors"] ==[]:
i_dir = ""
else:
i_dir = data["directors"][0]["peopleNm"]
# --> i번째 영화에 대한 필요한 정보 추출 & 변수화
#==> 이것들을 모아서 담아야함
tot_data.append([i_code,i_name,i_name_e,i_day,i_dir])
print("Done!")
tot_data
'''
[['20030047', '모노노케 히메', 'Princess Mononoke', '20030425', '미야자키 하야오'],
['20257037', '가족의 비밀', 'Family Secrets', '20250910', '이상훈'],
['20246333', '3670', '3670', '20250903', '박준호'],
['20256706', '섹스에 중독된 소녀 그리고 유부녀-무삭제', '', '', '성기만'],
['20240549',
'베르메르: 위대한 전시회',
'Vermeer: The Greatest Exhibition',
'20250917',
'데이비드 비커스태프'],
['20256883', '썸머 블루 아워', 'Summer Blue Hour', '', ''],
['20257161', '국보', 'KOKUHO', '', '이상일'],
['20256742', '일대무사', '100 YARDS', '', ''],
['20257095', '명탐정 코난: 17년 전의 진상', 'Detective Conan', '', '야마모토 야스이치로'],
['20228988', '보스', 'BOSS', '', '라희찬'],
['20233039', '살인자 리포트', 'MURDER REPORT', '20250905', '조영준'],
['20256526',
'브레드이발소: 베이커리타운의 악당들',
'Bread Barbershop : The Bakerytown Baddies',
'20250927',
'정지환'],
['20241102', '홍이', 'Red Nails', '', '황슬기'],
['20247429', '세계의 주인', 'The World of Love', '', '윤가은'],
....
'''
#위의 정보를 2차원에 오와 열이 맞춰져 있으므로 => 2차원 DF로 택갈이하자
movie_df = pd.DataFrame(
data = tot_data,
columns = ["movieCd", "movieTitle", "movieETitle","openDay","DirName"]
)
movie_df.head(10)
movie_df.tail(10)
### 개별 영화 정보 dict --> 모아두는 것은 [] 전체 리스트로 담자!!!
# 할 일 : 위의 정보들을 DF에 담아보자!!!
tot_data = [] # --> 개별 원소를 리스트로 담아서, 전체를 리스트 포장 2D
for idx, data in enumerate(movie_data["movieListResult"]["movieList"]):
# data : 개별 영화 정보 dict
# idx : 정수 인덱스,,,
i_code = data["movieCd"]
i_name = data["movieNm"]
i_name_e = data["movieNmEn"]
i_day = data["openDt"]
if data["directors"] ==[]:
i_dir = ""
else:
i_dir = data["directors"][0]["peopleNm"]
#---> i번쨰 영화에 대한 필요한 정보 추출!!!& 변수화!!
# ===> Dict 포장!!!
tot_data.append( {"movieCd":i_code, "movieTitle":i_name,
"movieETitle":i_name_e, "openDay":i_day,
"DirName":i_dir})
print("Done!!")
이제 후처리를 해보자
- 개봉일에 대한 정보를 바탕으로 → 년/월/일 컬럼을 추가 ⇒ 생성해보자
- movieCd 컬럼의 값/의미를 보니 → 코드값/키값/인덱스로 지정해도 될 듯? ⇒유니크한 값들인지 체크.. 유니크하다면? ⇒⇒ DF에서 가로(개별 영화에 대한 접근 우회) 인덱스 하자
"20240424"[:4]
#2024
"20240424"[4:6]
#04
"20240424"[6:]
#24
movie_df.loc[:,"openDay"].apply( lambda x : x[:4])
movie_df["year"] = movie_df.loc[:,"openDay"].apply( lambda x : x[:4])
movie_df["month"] = movie_df.loc[:,"openDay"].apply( lambda x : x[4:6])
movie_df["day"] = movie_df.loc[:,"openDay"].apply( lambda x : x[6:])
movie_df.head(3)
movie_df.head(10)
movie_df.head(3)
# --> movieCd 컬럼의 값들이 유니크한지 체크
# ===> DF의 가로줄 index로 부여하려고 하기에
len(movie_df.loc[:,"movieCd"].unique()) == len(movie_df) #movieCd 중첩 없으므로 pk로 쓸 수 있겠다
#True
#기존 컬럼을 DF의 가로줄 인덱스 지정 :set_index
movie_df.set_index("movieCd")
movie_df.set_index("movieCd", inplace = True)
movie_df.head()
#DF에서 FM적으로 1번 영화에 대한 정보를 접근해보자
movie_df.iloc[0,:]
'''
2025A733
movieTitle 울 엄마는 마피아
movieETitle Mafia Mamma
openDay
DirName 캐서린 하드윅
year
month
day
dtype: object
'''
movie_df.loc["2025A733", : ]
'''
2025A733
movieTitle 울 엄마는 마피아
movieETitle Mafia Mamma
openDay
DirName 캐서린 하드윅
year
month
day
dtype: object
'''
참고) 지금까지 수집한 정보를 일단 저장을 해두고 싶다
- 로컬 파일에 저장→ 파일) csv, excel, ….
- csv : 값 + 구분자
- excel : 값 + 양식/꾸밈
참고) colab에서 하고 있어서 일단 여기에 저장을 하겠다
/content/sample_data
#colab은 운영체제가 윈도우 아니고 리눅스
# ==> 리눅스때매 한글에서 문제가 발생할 수 있음(mac과 윈도우 왔다갔다해도 그럼 )
# 윈도우쪽 한글 : cp949
# 리눅스 : utf-8
movie_df.iloc[:-1,:].to_csv('/content/kobis_api.csv', sep='@',encoding="cp949")
movie_df.iloc[:-1,:].to_csv('/content/kobis_api_utf-8.csv', sep='@',encoding="utf-8")
#csv 파일을 불러들이는 방법
#pd.read_csv()
temp_df = pd.read_csv('/content/kobis_api_utf-8.csv',
sep ="@", encoding = "utf-8")
temp_df.head()ㄴ
#excel로 내보내기
movie_df.to_excel('/content/kobis_api_excel.xlsx')
#-> 이상 없이 엑셀 잘 열린다
#++ 실제 나중에서는 DB에 직접 올리거나 처리하는 경우도 있음
하고자하는 추가 작업
- 앞에서 한 50개 영화에 대한 상세 정보 추가 ⇒ 세로/옆으로 확장! 속성을 추가하자
-
- 장르에 대한 정보 추가 (1번 장르만 하자,,정의, 없으면 빈칸)
-
- 출연한 배우의 수 추가 (없으면 0)
-
- 출연한 배우 중에서 1번 배우가 있다면 → 메인 배우에 대해서 배역 이름, 배우의 이름 (없으면 빈칸)
- ⇒⇒ kobis API의 영화상세정보에서,,,,
개별 영화에 대한 상세 정보 제공하는 기능
- 영화 상세정보 : 개별 영화에 대한 상세정보
- 요청사항 : key + 궁금한 1개 영화에 “코드값”
- 기본 url http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json
- 본인 key 정보 + 요청하려는 영화 코드값
movie_df
#개별 영화에 대한 상세 정보 제공하는 기능
# ==> 영화 상세정보 : 개별 영화에 대한 상세정보
# test : 20124079 ==> 광해 영화에 대해서 체크!!!!
base_url = "<http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json>"
# key, movieCd
key="84f5fd2eb892d013291cc10dcba3f787"
movieCd = "20124079"
# url
url = base_url+"?key="+key+"&movieCd="+movieCd
url
##<http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json?key=84f5fd2eb892d013291cc10dcba3f787&movieCd=20124079>
# --> 위의 요청에 대한 사항을 직접 파이썬에서 요청해서 받아보세요!!!
res = urllib.request.urlopen( url )
temp_data = json.loads( res.read().decode("utf-8"))
temp_data
type(temp_data)
temp_data.keys()
temp_data["movieInfoResult"]["movieInfo"].keys()
## 광해 영화에 대해서 상세정보를 출력을 해보세요!!
# Q1) 장르에 대한 정보를 출력해보세요!! --> generes : 여러개 면 맨 처음
# Q2) 출연한 배우의 수
# Q3) 배우 정보가 있다면 1번 배우의 이름을 출력
# Q4) 배우 정보가 있다면 1번 배우의 배역을 출력
# Q1) 장르에 대한 정보를 출력해보세요!! --> generes : 여러개 면 맨 처음
temp_data["movieInfoResult"]["movieInfo"]["genres"]
##[{'genreNm': '사극'}, {'genreNm': '드라마'}]
temp_data["movieInfoResult"]["movieInfo"]["genres"][0]["genreNm"]
##사극
# Q2) 출연한 배우의 수
type(temp_data["movieInfoResult"]["movieInfo"]["actors"])
##list
len(temp_data["movieInfoResult"]["movieInfo"]["actors"])
##36
# Q3) 배우 정보가 있다면 1번 배우의 이름을 출력
temp_data["movieInfoResult"]["movieInfo"]["actors"][0]
##{'peopleNm': '이병헌',
## 'peopleNmEn': 'LEE Byung-hun',
## 'cast': '광해/하선',
## 'castEn': ''}
temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["peopleNm"]
##이병헌
# Q4) 배우 정보가 있다면 1번 배우의 배역을 출력
temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["cast"]
##광해/하선
# 추가적인 상세 정보를 DF에 확장하고 싶다!!!
# ==> 기존 DF에 추가정보 기록할 공간을 만들려고 함!!
# ---> 1번 장르 이름, 배우 수, 1번 배우 이름/배역
movie_df["Gen"]=""
movie_df["ActNum"]=""
movie_df["ActName"]=""
movie_df["ActCast"]=""
movie_df.head()
# Step1) 지금 개인별로 수집한 영화 DF에서
# --> i번째 영화에 대한 상세 정보 요청하는 url (json)
# 2) 요청하고--> 받고 --> 필요 정보 추출!!
# 3) 기존 DF에 기록!
for i in movie_df.index:
print(i)
#20030047
#20257037
#20246333
#20256706
#20240549
#20256883
#20257161
# ...
base_url = "<http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json>"
key="84f5fd2eb892d013291cc10dcba3f787"
for i in movie_df.index:
#i번째 영화에 대한 상세 정보를 요청하는 url 생성
url = base_url +"?key="+key +"&movieCd="+ str(i)
#통신작업
temp_res = urllib.request.urlopen(url)
temp_data = json.loads(temp_res.read().decode("utf-8"))
# --> temp_data에는 i번째 영화의 상세 정보가 담겨있음
# 1) 장르
if temp_data["movieInfoResult"]["movieInfo"]["genres"] != []:
print(temp_data["movieInfoResult"]["movieInfo"]["genres"][0]["genreNm"])
else:
print("장르X")
# 2) 배우수 --> 배우에 대한 정보가 있다면 무조건 1명 이상은 존재!!!
if temp_data["movieInfoResult"]["movieInfo"]["actors"] != []:
print( len( temp_data["movieInfoResult"]["movieInfo"]["actors"] ))
print( temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["peopleNm"])
print( temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["cast"])
else:
print("배우 정보 X")
print("1번 배우 없음!")
print("1번 배우 배역 없음!")
print("*"*80)
print("Done!!")
#얘는 왜 돌아가면서 하나씩 띡띡 올라오냐?
# 서버에 계속 요청하는 것임
#실제로 사이트에서 긁어올 때는 이러면 차단 당함, 이러면 안 됨
#import time -> time.sleep() 사용을 위해 임포트
###이제 df에 담아보자
base_url = "<http://www.kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieInfo.json>"
key="84f5fd2eb892d013291cc10dcba3f787"
for i in movie_df.index:
# i번째 영화에 대한 상세 정보를 요청하는 url 생성!!
url = base_url +"?key="+key +"&movieCd="+ str(i)
# 통신 작업
temp_res = urllib.request.urlopen(url)
temp_data = json.loads(temp_res.read().decode("utf-8") )
# --> temp_data에는 i번째 영화의 상세 정보가 담겨!!!
# 1) 장르
if temp_data["movieInfoResult"]["movieInfo"]["genres"] != []:
movie_df.at[i, "Gen"] = temp_data["movieInfoResult"]["movieInfo"]["genres"][0]["genreNm"]
#print(temp_data["movieInfoResult"]["movieInfo"]["genres"][0]["genreNm"])
else:
movie_df.at[i, "Gen"] = "X"
#print("장르X")
# 2) 배우수 --> 배우에 대한 정보가 있다면 무조건 1명 이상은 존재!!!
if temp_data["movieInfoResult"]["movieInfo"]["actors"] != []:
movie_df.at[i,"ActNum"] = len( temp_data["movieInfoResult"]["movieInfo"]["actors"] )
movie_df.at[i,"ActName"] = temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["peopleNm"]
movie_df.at[i,"ActCast"] = temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["cast"]
#print( len( temp_data["movieInfoResult"]["movieInfo"]["actors"] ))
#print( temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["peopleNm"])
#print( temp_data["movieInfoResult"]["movieInfo"]["actors"][0]["cast"])
else:
movie_df.at[i,"ActNum"] = "0"
movie_df.at[i,"ActName"] = "X"
movie_df.at[i,"ActCast"] ="X"
#print("배우 정보 X")
#print("1번 배우 없음!")
#print("1번 배우 배역 없음!")
print("*"*80)
#time.sleep(2) #보통 데이터 불러올 때 이거 안 하면 블락 당하거나 서버 다운될지도...
print("Done!!")
movie_df #잘 만들어졌나 확인'데이터분석 > Pandas' 카테고리의 다른 글
| [Python] Pandas 07 _ json_kobis_api (2) | 2025.08.20 |
|---|---|
| [Python] Pandas 06 _ kobis_api_xml (0) | 2025.08.20 |
| [Python] Pandas 04 _ json (0) | 2025.08.19 |
| [Python] Pandas 03 _ pandas_2D_DataFrame (3) | 2025.08.19 |
| [Python] Pandas 02 _pandas_1D_Series (2) (0) | 2025.08.19 |