pandas를 가지고 데이터를 주고 받을 때
- 웹 데이터 : json, xml, html 등..
- 파일 데이터 : 다양한 양식들이 존재 (R, SAS, 엑셀 ,,,,,etc)
- 대표적인 양식 : csv, exel(xlsx)
- pandas를 가지고
- 데이터를 불러올 때 : pd.read~
- 데이터를 출력할 때 : pd. to ~~
- 개인프로젝트 할 때 중간 중간 저장을 해야 할 때
- 중간중간 내 pc에 저장
- 팀플로 하면 개인이 맡은 부분을 공유
- csv
- https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
- csv 파일
- 값들을 전달하고자 하는 것이 목적!!!!
- 구별자 sep : ",”
- ⇒ sep는 내가 전달하는 데이터의 값을 생각하고 지정!!!!
- excel 파일
- 값 + 꾸밈(양식)
- JSON/XML
- ---- html : csv --- excel
참고) Colab 환경에 한해서
- 직접 파일 업로드를 하면 : 꺼지면 없어져요~~~
- +++ 다시 또 하려면,,,내가 직접 또 업로드를 해야하는 귀찮음;
- ⇒ 조별 프로젝트 : 구글 드라이브하고 연동해서 사용하시는 것을 추천!!
# m1) 구글 드라이브에 직접 나의 구글 드라이브 마운트!!!
path = '/content/drive/MyDrive/0_ASAC_9기_202508/3_pandas/2_sampledata/01_olive.csv'
# m2) 내가 직접 파일을 드래그 + 선택해서 업로드
path = '/content/01_olive.csv'
# m3) 구글 드라이브 파일을 공유!!
# --> colab은 이미 자기네 구글드라이브 다운로드 할 수 있는 패키지를 설치!!
# anaconda는 없음!!!!
# --> !gdown 공유된파일의id
!gdown 106GjVssQBdzOXr5WXawGt0v8h1OKgtKI
'''
Downloading...
From: <https://drive.google.com/uc?id=106GjVssQBdzOXr5WXawGt0v8h1OKgtKI>
To: /content/01_olive.csv
100% 29.0k/29.0k [00:00<00:00, 51.1MB/s]
'''
path = '/content/01_olive.csv'
# 참고 : 경로 r''폴더경로를 알아서 잘 할꺼에요.....
data = pd.read_csv(path, sep=",")
data.head()

path = '/content/01_olive.csv'
# 참고 : 경로 r''폴더경로를 알아서 잘 할꺼에요.....
data = pd.read_csv(path, sep="@")
data.head()

data = pd.read_csv(path, sep=",")
data.head()

- 처음 컬럼에 이상한 값이 존재한다
- 원본 데이터에 값이 없었기에 Unnamed: 0
- Unnamed : 0 → id_area
- region : code
- 기존의 컬럼의 이름을 변경하자
chg_cols_dict = {"Unnamed: 0":"id_area","region":"code"}
data.rename(columns=chg_cols_dict, inplace=True)
data.head()

id_area 값이 중복이 안 될 것 같은데
- db에서 pk는 무조건 유니트
- 파일로 주고받다보니 실수로 중복된 값이 있을 수도 있음
- 체크하기 ***
len(data.loc[:, "id_area"].unique()) == len(data)
'''
True
'''
data.head()

data.tail()


아주 간단한 전처리
- id_area 컬럼의 값을 사람기준이 아니라 파이썬 기준 숫자로 변경!!
- 1.North-Apulia ==> 0_North-Apulia
- 2.North-Apulia ==> 1_North-Apulia
- …
- 572.West_Liguria ==> 571_West_Liguria
- ⇒ 간단한 작업인데 ...정의!!!
- 규칙: .을 중심으로 분리
- 앞의 숫자: -1을 줄이고
- 뒤의 지역 : 그대로 + 앞에 _문자를 붙여서
- 앞의 숫자: -1을 줄이고
- apply + lambda 위의 규칙을 작성
"1.North-Apulia".split(".")
'''
['1', 'North-Apulia']
'''
"1.North-Apulia".split(".")[0]
'''
1
'''
int("1.North-Apulia".split(".")[0])-1
'''
0
'''
"1.North-Apulia".split(".")[1]
'''
North-Apulia
'''
str(int("1.North-Apulia".split(".")[0])-1) + "_" + "1.North-Apulia".split(".")[1]
'''
0_North-Apulia
'''

data.loc[:,"id_area"].apply(lambda x : str(int(x.split(".")[0])-1) + "_" + x.split(".")[1])
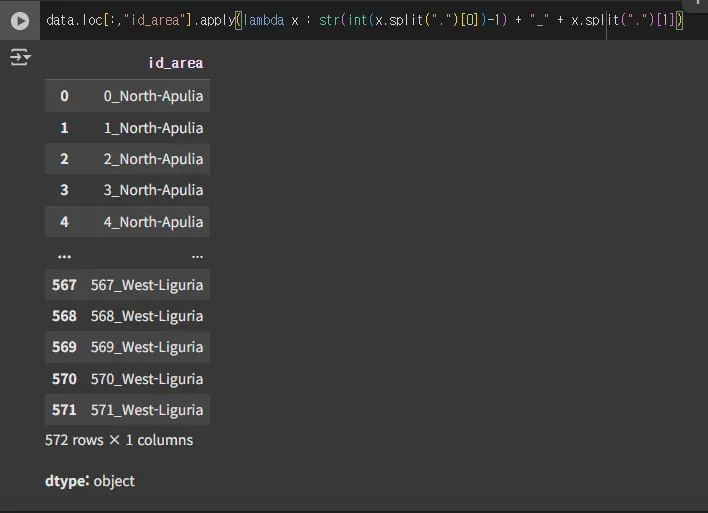
data.loc[:,"id_area"] = data.loc[:,"id_area"].apply( lambda x : str(int( x.split(".")[0])-1)+"_"+x.split(".")[1] )
data.head()

data.head()

참고) 데이터를 전처리하는 입장에서 apply + lambda 잘 활용하면 코드 작성이 편하다 → 그런데 속도는 그렇게 빠르지는 않다
기존의 palmitic 주어진 값을 좀 변경하고 싶다
- 1m 50cm == 150 cm = 1.5m
- ⇒ 1075 ---> 10.75
- ⇒ 1088 ---> 10.88
- 기존의 값을 100으로 나눠서 단위 변경!!!!
- apply + lambda
- 다른
data.loc[:, "palmitic"].apply( lambda x: x/100)

data.loc[:, "palmitic"] / 100

data.loc[:, "palmitic"] = data.loc[:, "palmitic"] / 100
data.head()
'''
/tmp/ipython-input-1435286582.py:1: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise in a future error of pandas. Value '[10.75 10.88 9.11 9.66 10.51 9.11 9.22 11. 10.82 10.37 10.51 10.36
10.74 8.75 9.52 11.55 9.43 12.78 9.61 9.52 10.74 9.95 10.56 10.65
10.65 13.15 13.21 13.59 13.78 12.95 12.75 13.36 13.09 13.4 12.99 12.21
12.45 12.85 12.48 13.56 12.6 12.61 13.04 13.44 13.23 12.92 12.54 13.12
12.13 13.59 12.66 12.98 12.72 12.78 11.84 13.82 11.83 12.61 11.98 12.25
13.39 11.32 13.81 14.09 13.06 13.72 13.36 14.01 13.9 14.32 14.12 13.66
13.83 12.83 12.96 12.87 13.51 12.41 12.67 12.35 12.55 14.54 13.47 13.64
14.1 13.84 14.12 14.1 15.09 13.17 12.86 12.73 14.63 13.99 14.13 13.69
14.88 13.23 13.11 12.86 13.8 13.94 13.24 12.9 13.61 13.87 13.69 13.03
13.46 13.69 13.05 13.51 12.83 14.49 13.1 13.6 13. 13.68 12.07 13.48
13.34 13.01 12.26 12.01 12.97 12.48 13.35 12.19 13.18 12.64 12.01 12.52
12.73 13.51 13.36 14.99 14.25 13.58 13.46 13.92 13.11 13.14 14.09 13.42
13.87 14.13 14.3 13.36 13.72 13.3 14.12 13.21 14.01 14.01 14.57 14.51
14.38 14.62 15.29 15.1 14.37 13.27 14.38 14.47 13.55 13.69 14.71 14.56
13.14 14.08 13.97 14.13 15.39 13.04 13.41 15.08 15.15 12.62 13.07 12.94
14.6 14.76 14.82 13.88 13.67 12.72 13.23 12.06 13.83 15.21 13.5 14.22
12.98 14.47 13.47 13.39 13.88 15.27 14.95 14.87 13.99 14.89 13.39 14.82
14.34 13.47 13.4 14.53 13.06 13.49 12.54 11.68 13.46 13.9 12.83 12.14
14.91 14.79 14.45 14.39 13.87 14.26 14.51 14.93 14.19 13.42 13.49 14.4
14.6 12.49 13.48 13.41 13.98 14.54 13.34 14.38 13.03 13.23 14.17 13.6
14.2 14.72 13.68 13.67 14.03 14.13 12.01 13.59 15.18 14.34 13.67 14.61
13.68 14.19 15.14 13.28 14.69 12.22 16.39 13.45 13.39 11.94 11.12 12.22
11.36 9.26 11.05 11.09 12.84 11.2 9.16 9.05 12.06 14.57 13.27 13.03
14.44 15.05 14.29 14.91 13.93 14.04 12.22 11.53 11.69 13.69 9.93 9.8
9.67 11.28 11.88 12.57 12.62 12.83 12.63 13.69 13.53 11.87 17.32 16.2
15.43 14.98 13.99 12.93 14.2 17.21 17.42 13.91 15.17 12.69 15.77 15.9
16.21 17.53 16.79 14.19 16.93 16.92 16.38 14.97 14.42 16.8 14.63 11.29
10.42 11.03 11.18 10.52 11.16 11.08 11.29 10.85 11.04 10.98 11.35 11.58
11.33 10.95 12.01 12.13 11.08 10.75 10.59 11.76 11.59 11.32 11.07 10.92
11.19 11.06 10.47 11.65 11.58 10.95 11.76 11.03 11.12 10.91 10.8 10.51
10.96 11.42 10.47 11.14 11.4 10.75 10.92 10.76 11.78 10.95 11.66 11.54
11.77 11.6 11.22 11.32 10.96 11.31 11.84 11.35 10.84 10.86 11.4 11.38
11.59 10.51 10.48 10.61 11.05 11.45 10.49 11.05 10.3 10.7 11.03 10.4
11. 11.18 10.65 11.31 10.8 10.75 10.4 11.28 10.6 11.03 11.1 10.91
10.94 11.31 11.75 10.76 11.2 11.52 11.41 10.98 11.26 10.87 11.15 11.78
11.62 10.85 10.85 10.9 10.8 10.9 11.05 10.6 10.5 11. 10.65 10.85
10.8 10.85 10.75 10.9 10.95 10.9 10.95 10.9 10.95 10.95 10.8 10.9
11.05 11.1 10.75 10.75 10.65 10.7 10.7 11. 10.75 10.5 10.9 10.5
10.75 10.98 11.05 11.1 10.58 11.15 11.05 10.72 11.1 11.1 10.55 11.
11.05 10.95 11.1 10.92 12.9 11.7 11. 11.2 11.6 12. 11.4 12.2
11.8 12.1 12.2 11.8 11.6 11.3 10.8 10.9 10.2 10.9 11.2 10.8
11.6 11. 10.5 10.9 11.2 11.2 11.9 11.7 11.2 11.9 14. 13.5
10.9 11.5 12.4 12.2 11.8 11.7 11.7 11.8 12. 11.4 11.6 11.3
11.5 11.1 11.5 11.8 10.2 6.1 11.9 11.1 10.2 10.7 10.1 10.6
10.6 10.3 11.2 10.3 10.7 11.4 10.9 9.8 9.8 9.6 9.9 10.6
12.4 10.6 10.2 9.7 11.8 10.6 9.9 10.1 10.4 10.4 10.2 10.2
10.1 9.2 10.3 9.6 10.3 10.1 10.2 11.2 10.9 11. 10.9 11.5
11.1 10.1 10.7 12.8 10.6 10.1 9.9 9.6 ]' has dtype incompatible with int64, please explicitly cast to a compatible dtype first.
data.loc[:, "palmitic"] = data.loc[:, "palmitic"] / 100
'''

data.head()

d_area 가로줄 인덱스로 써도 될 것 같다
⇒ 내가 만든 가로줄에 대한 인덱스 지정 : set_index
data.set_index("id_area", inplace=True)
data

### to_csv : 파일 경로 + 인코딩 + 틀[가로/세로 내가 만든](opt)
data.to_csv("/content/test_out_01.csv")
data.to_csv("/content/test_out_02.csv",
sep=",",
index=False)
data.to_csv("/content/test_out_03.csv",
sep=",",
index=False,
header=False)
참고) read_csv 파라미터
- sep="," # ==> 특정 구별하는 문자!!!
- header ⇒ csv 파일의 처음 1줄을 : header/ 컬럼이름으로 쓸지 말지..
path = '/content/01_olive.csv'
data = pd.read_csv(path, sep=",", header=None)
data.head()

path = '/content/01_olive.csv'
data = pd.read_csv(path, sep=",", header=None)
data.head()

3. skiprows : csv 파일을 몇 줄 건너 띄어서 읽기를 시작할까요
- why? → 앞에 내가 원하지 않는 정보들이 있고, 몇 줄 뒤에 원하는 정보가 시작할 때가 존재함 (라이센스, 법조항, 소유권 등…)
# 3) skiprows : csv 파일을 몇 줄을 건너띄어서 읽기를 시작할까요~~~
# ===> 왜 : 앞에 내가 원하지는 않은 정보들이 있고,,몇 줄 뒤에 원하는 정보가
# 시작할 떄가 존재!!( 라이센스, 법조항, 소유권~~~)
path = '/content/01_olive.csv'
data = pd.read_csv(path, sep=",", header=None)
data.head()

+++ 이정도는 부를 때 이슈가 되는 것들이어서 체크해야함
- 기타 자세한 것들은 메뉴얼을 보고 해도 되고
- 일단 불러들이고 전처리를 통해서 정리해도 상관 없음 (강사님은 보통 후자를 선택하심)
'데이터분석 > Pandas' 카테고리의 다른 글
| Selenium 01 _ selenium 설치 및 실행 (0) | 2025.08.22 |
|---|---|
| [Python] Pandas 11 _ pandas_m&a (5) | 2025.08.21 |
| [Python] Pandas 09 _ daum_site (2) | 2025.08.21 |
| [Python] Pandas 08 _ dart_site (5) | 2025.08.21 |
| [Python] Pandas 07 _ json_kobis_api (2) | 2025.08.20 |